
2023. 12. 26. 14:18ㆍTool
이 게시물은 2023년 12월 16일에 Tristan Bilot가 Medium에 개제한 "MLX vs MPS vs CUDA: a Benchmark"에 대해 번역, 첨언한 내용임을 밝힙니다.
👉MLX vs MPS vs CUDA: a Benchmark
Introduction
맥 사용자이면서 딥러닝에 관심이 많다면, 맥에서 무거운 모델들을 다루는 순간들을 기다려왔을텐데요.
애플에서 최근 맥북에 도입한 전용 칩에서 ML 모델을 효율적으로 돌릴 수 있는 프레임워크인 "MLX"를 출시했습니다.(현지 시간 12월 6일)
MLX는 애플에서 직접 개발한 머신러닝용 어레이 프레임워크인데요.
애플 실리콘의 CPU와 GPU를 활용해 벡터와 그래프 연산의 속도를 높일 수 있습니다.
그 중에서도 lazy evaluation이라는 프로그래밍 방법론을 사용하는데요.
연산이 실제로 필요할 때까지 연산을 지연시킴으로써 성능 향상을 향상합니다.
직접 가상환경을 생성해 MLX를 사용해보겠습니다.
가상환경 생성
아래 명령어를 통해 'mlx'라는 이름의 가상환경을 만들어준다.
# 'mlx'라는 가상환경에 파이썬 3.10 numpy, pytorch, scipy, requests 설치
CONDA_SUBDIR=osx-arm64 conda create -n mlx python=3.10 numpy pytorch scipy requests -c conda-forge
# mlx 가상환경 활성화
conda activate mlx
실제로 arm을 사용하고 있는지, 아래 명령어를 통해 확인할 수 있는데요.
아래 명령어의 결과물로 'arm'이 출력되면 됩니다.('i386'이면 안됨)
python -c "import platform; print(platform.processor())"
이제 pip 명령어를 사용해 MLX를 설치해주겠습니다.

mlx 패키지까지 설치가 완료되었는데요.
간단하게 터미널에서 작업을 진행해보도록 하겠습니다.
일단, 아래 깃허브에서 git clone을 진행해오면 됩니다.
GitHub - TristanBilot/mlx-GCN: MLX implementation of GCN, with benchmark on MPS, CUDA and CPU (M1 Pro, M2 Ultra, M3 Max).
MLX implementation of GCN, with benchmark on MPS, CUDA and CPU (M1 Pro, M2 Ultra, M3 Max). - GitHub - TristanBilot/mlx-GCN: MLX implementation of GCN, with benchmark on MPS, CUDA and CPU (M1 Pro, M...
github.com
# git clone 해오기
git clone https://github.com/TristanBilot/mlx-GCN.git
git clone 뒤에 있는 주소의 경우, 초록색 <Code> 버튼을 클릭한 뒤, HTTPS 주소를 클릭하시면 됩니다.
(파란색 화살표의 복사 버튼을 누르면 빨간색 네모 박스 안 레포지토리 url 복사)

git clone이 잘 완료되었는데요.
그렇다면, 다운 받은 mlx-GCN으로 이동해보겠습니다.
# mlx-GCN으로 이동
cd mlx-GCN
이동을 한뒤, ls 명령어를 통해 어떤 폴더들이 있는지 확인할 수 있습니다.
# 디렉토리 안 구성 확인
ls
어떤 구성요소들이 있는지 확인해보았는데요.
그 다음으로는 python main.py를 통해 파일을 실행해보도록 하겠습니다.
# main.py 실행
python main.py
main.py를 실행하면 Cora 데이터셋을 다운받고, train, test를 실행합니다.
CORA DATASET
cora 데이터셋은 인용 네트워크를 나타나는 데이터입니다.
2,708개의 학술 논몬을 7개의 class로 분류하며, 총 5,429개의 인용 네트워크를 가지고 있습니다.
학술 논문들의 이용 관계를 그래프 형태로 나타내며, 각 node(점)는 논문을 나타내고, Edge(점과 점을 잇는 선)는 논문 간의 인용 관계를 나타냅니다.


GCN Implementation
GCN(Graph Convolutional Networks: 그래프 합성곱 신경망) 모델은 그래프 뉴럴 네트워크(Graph Neural Network, GNN)의 일종으로 인접 행렬(adjaceney matrix)와 노드의 특성을 가지고 있는데요.
*Adjaceney Matrix
아래와 같은 그래프가 있을 때, 각 Node간에 연결(edge) 존재하면 1, 아니면 0으로 masking한 matrix
-> 즉, graph의 모양(topology)이 정의된 데이터

인접한 노드들(neighboring nodes)로부터 정보를 모아 node embedding 값을 계산합니다.
구체적으로 설명하자면, 각 노드는 인접한 노드의 특징의 평균 값을 구하는데요.
노드의 특징을 정규화된 인접 행렬로 곱하고, 노드의 차수로 조정합니다.
이 과정을 학습하기 위해, 피처들은 linear layer(선형 레이어)를 통해 임베딩 공간으로 투영하는 방식입니다.
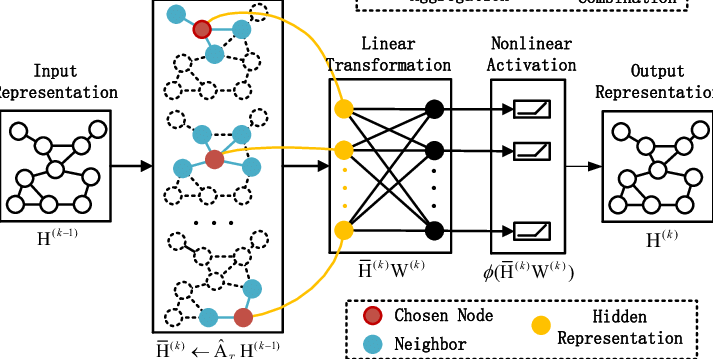
이제, 위에서 실행한 결과에 활용된 GCN 레이어와 GCN 모델 구현 과정을 살펴보겠습니다.
import mlx.nn as nn
class GCNLayer(nn.Module):
def __init__(self, in_features, out_features, bias = True):
super(GCNLayer, self).__init__()
self.linear = nn.Linear(in_features, out_features, bias)
def __call__(self, x, adj):
x = self.linear(x)
return adj @ x
class GCN(nn.Module):
def __init__(self, x_dim, h_dim, out_dim, nb_layers = 2, dropout = 0.5, bias = True):
super(GCN, self).__init__()
layer_sizes = [x_dim] + [h_dim] * nb_layers + [out_dim]
self.gcn_layers = [
GCNLayer(in_dim, out_dim, bias)
for in_dim, out_dim in zip(layer_sizes[:-1], layer_sizes[1:])
]
self.dropout = nn.Dropout(p = dropout)
def __call__(self, x, adj):
for layer in self.gcn_layers[:-1]:
x = nn.relu(layer(x, adj))
x = self.dropout(x)
x = self.gcn_layers[-1](x, adj)
return x
위 코드를 보면, MLX 코드는 Pytorch 코드와 매우 유사한데요.
self.gcn_layers 파트에서 차이를 보이고 있습니다.
MLX에서는 self.gcn_layers를 모듈의 리스트로 인스턴스화하는 반면,
Pytorch에서는 일반적으로 nn.Sequential을 활용합니다.
MLX와 Pytorch 코드의 차이점은 훈려파트에서부터 많은 차이점을 보이는데요.
gcn = GCN(
x_dim = x.shape[-1],
h_dim = args.hidden_dim,
out_dim = args.nb_classes,
nb_layers = args.nb_layers,
dropout = args.dropout,
bias = args.bias,
)
mx.eval(gcn.parameters())
optimizer = optim.Adam(learning_rate = args.lr)
loss_and_grad_fn = nn.value_and_grad(gcn, forward_fn)
# 훈련
for epoch in range(args.epochs):
# Loss
(loss, y_hat), grads = loss_and_grad_fn(
gcn, x, adj, y, train_mask, args.weight_decay
)
optimizer.update(gcn, grads)
mx.eval(gcn.parameters(), optimizer.state)
# Validation
val_loss = loss_fn(y_hat[val_mask], y[val_mask])
val_acc = eval_fn(y_hat[val_mask], y[val_mask])바로 눈에 띄는 차이점으로는 mx.eval()을 사용한다는 것인데요.
MLX에서는 계산이 지연되기 때문에 eval()이 종종 실제로 새로운 모델 매개변수를 업데이트한 후에 계산됩니다.
또 다른 주요 함수인 nn.value_and_grad()는 매개변수에 대한 손실을 계산하는 함수를 생성합니다.
첫번째 argumet는 현재 파라미터를 보유하는 모델이고, 두 번째 argument는 순전파(forward pass)와 손실을 계산하는데 호출 가능한 함수입니다.
이 함수가 반환하는 함수는 forward 함수와 동일한 argumet를 사용하는데요.
forward_fn을 다음과 같이 정의할 수 있습니다.
def forward_fn(gcn, x, adj, y, train_mask, weight_decay):
y_hat = gcn(x, adj)
loss = loss_fn(y_hat[train_mask], y[train_mask], weight_decay, gcn.parameters())
return loss, y_hat
forward_fn은 순전파를 진행하고, 손실을 계산하는 파트로 이루어져 있습니다.
loss_fn()과 eval_fn()은 다음과 같이 정의됩니다.
def loss_fn(y_hat, y, weight_decay = 0.0, parameters = None):
l = mx.mean(nn.losses.cross_entropy(y_hat, y))
if weight_decay != 0.0:
assert parameters != None, "Model parameters missing for LS reg."
l2_reg = sum(mx.sum(p[1] ** 2) for p in tree_flatten(paramters)).sqrt()
return l + weight_decay * l2_reg
return l
def eval_fn(x, y):
return mx.mean(mx.argmax(x, axis = 1) == y)
손실함수의 경우, 예측과 정답 값 사이의 교차 엔트로피를 계산하고 L2 Regularization을 진행하는데요.
L2 정규화가 아직 내장되어 있지 않기에 직접 코드를 통해 구현해줬습니다.
Pytorch와의 또 다른 점은, .cuda()나 to(device)와 같은 장치 할당이 필요없다는 점입니다.
애플 실리콘 칩의 통합 메모리 아키텍처가 있어 모든 변수가 동일한 공간에 공존하기 때문입니다.
CPU와 GPU 간 느린 속도의 데이터 전송 과정을 없애고 device mismatch등과 관련된 runtime error 문제를 없앨 수 있습니다.
LLAMA2 Implementation
MLX 공식 깃허브에서 다양한 예시들을 제공하고 있는데요.

저희는 여기서 LLaMA를 활용해보도록 하겠습니다.
일단, 깃허브를 clone 해오겠습니다.

git clone https://github.com/ml-explore/mlx-examples.git그 다음으로 mlx-examples가 있는 디렉토리로 이동해보겠습니다.
cd mlx-examples
굉장히 다양한 exmplaes들이 존재하는데요.
저희는 llms 안에 있는 llama를 활용해보겠습니다.
마찬가지로, llama 디렉터리로 이동해주겠습니다.
cd llms/llama
llama 디렉토리로 이동해 ls를 통해 어떤 파일들이 있는지 확인했는데요.
llama.py 파일을 활용해볼 예정입니다.
그 전에 llama 모델을 허깅페이스에서 다운받아보겠습니다.
필요한 패키지 먼저 설치를 진행해보겠습니다.
pip install huggingface_hub hf_transfer
마지막에 "successfully installed~" 메세지를 통해 잘 설치된 것을 확인했습니다.
그 다음으로는 아래 과정을 진행해보도록 하겠습니다.
export HF_HUB_ENABLE_HF_TRANSFER = 1huggingface-cli download --local-dir Llama-2-7b-chat-mlx mlx-llama/Llama-2-7b-chat-mlx
모델이 잘 다운로드가 되었는데요.
다운로드된 모델에 간단한 테스트를 진행해보겠습니다.
python mlx-examples/llama/llama.py --prompt "My name is " Llama-2-7b-chat-mlx/ Llama-2-7b-chat-mlx/tokenizer.model
TO BE CONTINUED
Conclusion
MLX 장점
- 애플 전용 칩 '애플 실리콘'의 성능 활용해 로컬에서 딥러닝 모델 실행할 수 있음
- 문법은 대부분 torch와 유사하며, Jax에서도 영감 받은 내역 있음
- 디바이스 없이, 모든 것이 통합된 메모리에 있음
MLX 단점
- 프레임워크가 나온지 얼마 되지 않아, 아직 많은 기능이 있지 않음
- 특히, Graph ML의 경우, 현재 sparse operation과 scaterring API가 가능하지 않아 MLX상에서 message passing GNN을 구축하는 것이 복잡함
- 새로운 프로젝트이기에 MLX와 관련된 documentation이나 community discussion이 현재 부족한 상황
참고
MLX: Apple silicon용 Mahcine Learning 프레임워크 - 01. Quick-start
그래프 튜토리얼: Graph & Deep Walk
1. Random Walk 2. Node Embedding 3. Deep Walk (Word2Vec - Skip-gram) 4. Node Classification 반가워요, GUG 여러분! 그래프 튜토리얼의 가이드 Erica 입니다✨🚀 우리는 저번 시간에, Graph를 구성하는 개념 요소들을 만나
www.graphusergroup.com
'Tool' 카테고리의 다른 글
| [Lilys AI] AI vs 사람, 누가 더 요약을 잘할까? (1) | 2024.05.02 |
|---|---|
| PEFT(효율적 파라미터 파인 튜닝) 활용한 성능 최적화: 프롬프트 튜닝 딥다이브 (0) | 2023.12.13 |
| Inductive Bias (0) | 2023.03.27 |