
2023. 12. 13. 16:10ㆍTool
이 게시글은 2023년 11월 27일 Akriti Upadhyay가 medium에 게재한 "Optimizing Performance with PEFT: A Deep Dive into Prompt Tuning" 글에 대한 번역과 함께 첨언한 내용임을 밝힙니다.
👉원문: "Optimizing Performance with PEFT: A Deep Dive into Prompt Tuning"
Optimizing Performance with PEFT: A Deep Dive into Prompt Tuning
Elevate Your Language Model’s Performance with Advanced Prompt Optimization
medium.com
목차는 다음과 같습니다.
앞에서는 관련 개념을 설명한 후, 실제로 코드를 활용해 PEFT를 진행해보겠습니다.
|

Introduction
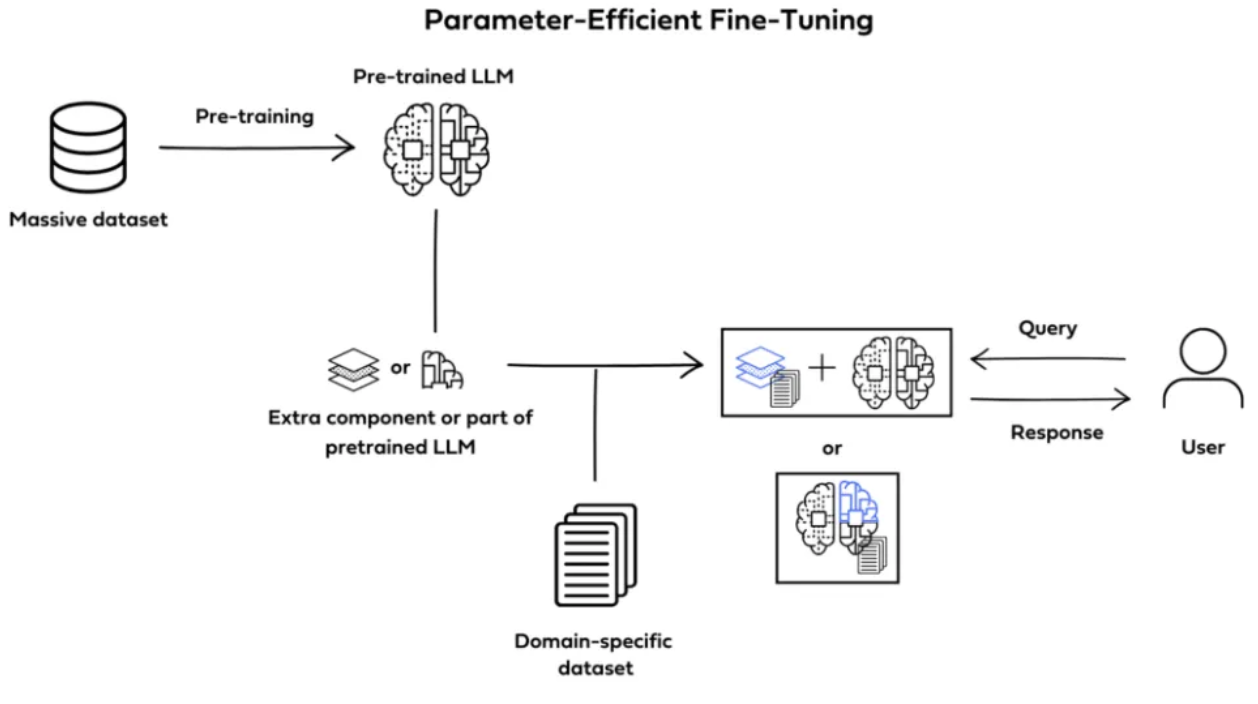
PEFT(Parameter Efficient Fine-tuning, 이하 PEFT)는 사전 훈련된 거대 언어 모델을 특정 상황에 적용할 때, 대부분의 파라미터를 freeze하고, 소수의 모델 파라미터만 fine-tuning하는 기법인데요.
모델이 점점 거대해지면서 일반 GPU로는 사용 목적에 맞게 파인튜닝이 어려워지자 나오게 된 개념으로 이해하시면 될 것 같습니다.
PEFT를 사용하면 모델의 성능을 유지하면서 파라미터의 개수를 줄여, 훈련 시간과 학습에 소요하는 메모리 비용을 줄일 수 있다는 장점이 있습니다.
PEFT를 활용할 경우, "catastrophic forgetting" 문제에 대한 위험도 적은데요.
"castographic forgetting"는 새로운 정보를 학습하게 될때, 기존에 학습한 일부의 지식에 대해서는 망각을 하게 되는 현상을 의미합니다.
PEFT는 사전 훈련된 모델, 구조화된 프롬프트를 통해 과제별 성능을 최적화해서 NLP 분야에서 혁신적인 방법론인데요.
PEFT를 활용할 경우, 많은 양의 라벨 데이터에 대한 필요가 없어집니다.
혁신적인 방법의 프롬프토 튜닝을 사용하기 때문에 제한된 라벨링 데이터만으로도 특정 과제에 대한 효율적인 파인 튜닝이 가능합니다.
따라서, 높은 비용의 데이터셋 구축 혹은 적은 양의 데이터셋에도 활용할 수 있습니다.
Prompt Tuning
프롬프트 튜닝 개념부터 알아보도록 하겠습니다.
프롬프트 튜닝은 언어 모델의 성능을 최적화하기 위한 기술입니다.
모델에게 전달되는 입력 프롬프트를 정제/조정하여 더 정확하고, 관련성 높은 답변을 유도하는 과정입니다.
프롬프트 튜닝의 목표는 다양한 프롬프트 조합을 반복적으로 조합해서 모델의 출력을 향상하는 데에 있습니다.

프롬프트 튜닝 작동 순서
- Understanding the Model(모델에 대한 이해)
프롬프트 튜닝을 하기 전, 사용하는 언어 모델에 대한 철저한 이해 필요
모델의 구조, 강점, 제약 사항들을 사전에 파악한다면 효과적인 프롬프트 작성에 도움이 됨 - Initial Prompt Design(초기 프롬프트 설계)
일반적으로 특정 과제/요청에 맞는 초기 프롬프트 작성으로 시작
초기에 작성된 이 프롬프트는 언어 모델에게 입력값으로 전달되고, 그 결과로 생성된 결과는 관련성, 정확성을 분석하기 위해 검토됨 - Fine-Tuning Parameter(파라미터 파인 튜닝)
어떤 언어 모델은 사용자들이 temperature 혹은 샘플링을 적용할 때 매개변수를 조절할 수 있게끔 함
이런 파라미터들(temperature or sampling)은 모델 응답의 다양성과 창의성에 영향을 미침
이런 파라미터들을 파인튜닝하는 것이 프롬프트 튜닝 과정의 하나 - Monitoring and Evaluation(모니터링 및 평가)
프롬프트 튜닝 과정동안, 정교한 모니터링과 평가 시스템 수립하는 것이 중요
생성된 출력물들의 품질을 체계적으로 평가하고, 에러들의 패턴을 파악하여 이 정보들을 추후 프롬프트 조정하는 과정에 활용하게 됨 - Incorporating Human Feedback(관리자 피드백과 통합)
프롬프트 튜닝에서 관리자의 피드백은 매우 중요한 역할 담당
모델의 응답을 평가하고, 최종 사용자로부터 피드백을 수집하여 지속적으로 프롬프트를 개선할 수 있음
사람이 개입하는 이러한 루프식 접근은 모델 성능의 지속적인 향상으로 연결됨
Parameter Efficient Fine Tuning(PEFT)
PEFT는 Hugging face(허깅페이스)에서 소개한 혁신적인 방법인데요.
transformer(트랜스포머) 구조에 기반한 거대 언어 모델(large language models: LLMs)을 학습하고 배포하는 과정에서의 불편함을 해결하기 위한 대안책입니다.
특히, PEFT는 거대 언어 모델을 downstream 과제들에서 미세 조정할 때 발생하는 계산 및 저장 비용과 관련된 문제를 해결하는데 집중하고 있습니다.

Key Features and Concepts(주요 내용과 컨셉)
- Reduced Parameter Fine-tuning(축소된 파라미터 파인튜닝)
사전 학습된 LLM 모델에서 대다수의 파라미터를 고정해 소수의 추가적인 파라미터만 파인튜닝하는 것이 중점
선택적 파인튜닝으로 계산적 요구가 급격하게 감소하는 효과 - Overcoming Catastrophic Forgetting(치명적 망각 문제 극복)
Catastrophic Forgetting 문제는 LLM 모델 전체를 파인 튜닝하는 과정에서 발생하는 현상인데, PEFT를 활용하여 치명적 망각 문제를 완화할 수 있음
PEFT를 활용하면 사전 훈련된 상태의 지식을 보존하며 새로운 downstream task에 대해 학습할 수 있음 - Application Across Modalities(여러 모달리티 적용 가능)
PEFT는 기존 자연어처리(Natural Language Process: NLP) 영역을 넘어서 다양한 영역으로 확장 가능함
스테이블 디퓨전(stable diffusion) 혹은 Layout LM 등의 포함된 컴퓨터 비전(Computer Vision: CV) 영역, Whisper나 XLS-R이 포함된 오디오 등의 다양한 마달리티에 성공적으로 적용됨 - Supported PEFT Methods(사용 가능한 PEFT)
라이브러리에서 다양한 PEFT 방법을 지원함
LoRA(Low-Rank Adaption), Prefix Tuning, 프롬프트 튜닝 등 각각의 방법은 특정한 미세 조정 요구 사항과 시나리오에 맞게 사용할 수 있도록 설계됨

사용 사례 & 예시
- Consumer Hardware Tuning(소비자 하드웨어에서 튜닝 가능)
PEFT는 30억 개 파라미터 가진 bigscience/T0_3B와 같은 거대 언어 모델에 적용되어 제한된 RAM 가진 소비자 하드웨어에서 동작함
엔비디아 GeForce RTX 2080 Ti 혹은 GeForce RTX 3080와 같은 GPU에서도 튜닝이 가능함 - INT8 Tuning in Google Colab(구글 코랩에서 8비트 정수 튜닝)
PEFT는 INT8(8-bit integer: 8 비트 정수) 튜닝으로의 기능 확장
구글 코랩 환경에서 67억 개 파라미터 가진 OPT-6.7b 모델 튜닝하는 과정 보여줌
*OPT: Open Pre-trained Transformer Language Models - Stable Diffusion Dreambooth(스테이블 디퓨전 dreambooth에서 활용)
dreambooth는 2022년 8월경에 구글과 보스턴 대학교 연구진에 의해 개발
간단하게 개인화가 가능한 text-to-image 디퓨전 모델로, 적은 수의 이미지만으로 기존의 모델을 오염시키지 않고 학습이 가능해 개인이 더 손쉽게 파인 튜닝이 가능하다는 특징 가지고 있음
PEFT를 사용해 11GB RAM 가진 하드웨어(엔비디아 Geforce RTX 2080 Ti 및 Geforce RTX 3080)에서 스테이블 디퓨전 dreambooth 훈련하는데 활용 가능
facebook/opt-6.7b · Hugging Face
🏆 HuggingFaceH4/open_llm_leaderboard 📉 upstage/open-ko-llm-leaderboard 😻 Sharathhebbar24/One-stop-for-Open-source-models 🏆 gsaivinay/open_llm_leaderboard 🔥 joaogante/assisted_generation_benchmarks 🔥 hallucinations-leaderboard/leaderboard
huggingface.co
bigscience/T0_3B · Hugging Face
T0 - Multiple-Choice QA: CommonsenseQA, DREAM, QUAIL, QuaRTz, Social IQA, WiQA, Cosmos, QASC, Quarel, SciQ, Wiki Hop- Extractive QA: Adversarial QA, Quoref, DuoRC, ROPES- Closed-Book QA: Hotpot QA*, Wiki QA- Structure-To-Text: Common Gen, Wiki Bio- Sentime
huggingface.co
PEFT로 훈련해 보기
PEFT로 훈련하는 과정은 선택한 PEFT 방법에 해당하는 설정을 생성하고, PEFT 라이브러리 활용해 기본 트랜스포머 모델을 wrapping, 변경된 설정으로 모델을 학습시키는 과정을 포함하는데요.

결과로 나온 모델은 inference를 위해 저장할 수 있으며, 훈련이 진행된 파라미터에 대한 가중치만을 포함하고 있습니다.
Implementing Prompt Tuning with PEFT(PEFT로 실제 프롬프트 튜닝 진행)
그렇다면, 이제 실제로 PEFT 라이브러리를 활용해 프롬프트 튜닝을 진행해 보겠습니다.
먼저, 필요한 라이브러리 설치부터 진행하겠습니다.
필요 라이브러리 설치
!pip install -q peft==0.4.0
!pip install -q transformers
!pip install -q datasets사용 라이브러리 가져오기
코드 적용에 필요한 모듈들을 import 해보겠습니다.
# 트랜스포머 라이브러리에서 사용할 클래스, 기능 가져오기
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer, DataCollatorForLanguageModeling
# 데이터셋 라이브러리
from datasets import load_dataset
# peft 라이브러리
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit, PeftModel, PeftConfig
# huggingface_hub 라이브러리
from huggingface_hub import notebook_login
import os
import time사전 학습된 모델 가져오기
텍스트 생성 위한 foundation casual LM로 bloomz 모델을 사용하겠습니다.
이 모델은 다국어 데이터셋에서 학습이 되었습니다.
#사용할 사전 학습 모델 지정
model_name = "bigscience/bloomz-560m"
#사전 학습 모델에 사용할 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
#지정한 모델 이름 사용해 사전 학습된 casual LM 로드
foundation_model = AutoModelForCausalLM.from_trained(model_name)
텍스트 생성(파인 튜닝 전)
파인튜닝을 하기 전, 모델에게 다음 입력 문장에 대해 새로운 구절 생성하도록 요청해 보겠습니다.
# 지정된 토크나이저 사용해 입력 텍스트 토큰화
input1 = tokenizer("Two things are infinite:", return_tensors = "pt", padding = True)
# input_ids와 attention_mask 기반해 사전 학습된 파운데이션 모델 사용해 텍스트 생성 요청
foundation_outputs = foundation_model.generate(
input_ids = input1["input_ids"],
attention_mask = input1["attention_mask"],
max_new_tokens = 7,
eos_token_id = tokenizer.eos_token_id
)
# 생성된 token id를 사람이 읽을 수 있는 텍스트로 디코딩
decoded_output = tokenizer.batch_decode(foundation_outputs, skip_special_tokens = True)
# 디코딩된 텍스트 출력(생성된 결과물 사람이 읽을 수 있는 형태로 출력)
print(decoded_output)
input1으로 들어간 문구가 "무한한 2개:"였는데요.
time and space(시간과 공간)가 생성되어 나왔습니다.

출력 결과물이 나쁘지 않은데요.
intpu1으로 들어간 문구의 경우, 알버트 아인슈타인(Albert Einstein)이 남긴 영어 명언인데요.
원래는 "Two things are infinite: the universe and human stupidity"(우주와 인간의 어리석음은 무한하다)입니다.
bloomz이 사전 학습한 데이터셋에는 영감을 주는 영어 명언에 관한 내용이 없었습니다.
따라서, bloom-560 모델을 Abirate/english_quotes라고 하는 데이터셋에 파인 튜닝을 해보려고 합니다.
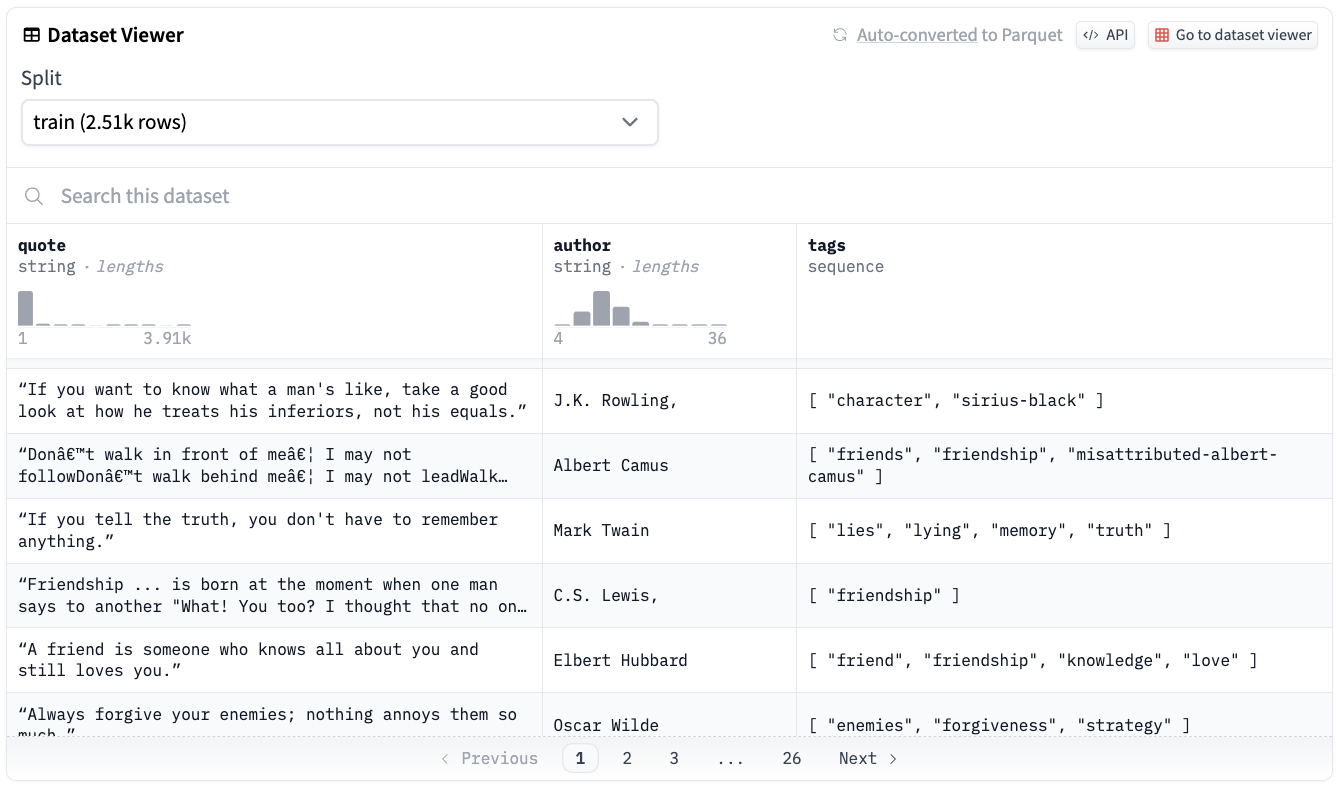
Abirate/english_quotes 데이터셋에는 영감을 주는 영어 명언들이 포함하고 있는데요.
해당 데이터셋으로 파인튜닝을 진행해 더 많은 명언을 생성할 수 있는지 확인해 보겠습니다.
데이터셋 확인(토크나이징, 인코딩, 디코딩)
# dataset 라이브러리 내 load_dataset 기능 활용해 "english_quotes" 데이터셋 가져오기
data = load_dataset("Abirate/english_quotes")
# 지정된 토크나이저 활용해 데이터셋 명언 토큰화
data = data.map(lambda samples:tokenizer(samples["quote"]), batched = True)
# 훈련 샘플 일부 선택(처음 50개)
train_sample = data["train"].select(range(50))
# train_sample 출력해보기
display(train_sample)
데이터셋을 다운로드해서 토큰화를 진행해보았는데요.
해당 데이터셋에 어떤 명언들이 담겨있는지 간단히 조회도 해볼 수 있습니다.
몇 개의 명언이 있는지는 다음과 같이 조회가 가능합니다.
# data train 개수
data['train'].shape
총 2,508개의 명언이 포함되어 있는데요.
어떤 명언들이 포함되어 있으며, author, tags는 어떻게 구성되어 있는지 다음과 같이 조회가 가능합니다.
# quotes 상위 10개 조회
data['train']['quote'][:10]
# author 상위 10개 조회
data['train']['author'][:10]
# tags 상위 10개 조회
data['train']['tags'][:10]
프롬프트 튜닝
프롬프트 튜닝은 soft prompts 혹은 가상 토큰(virtual token)의 random(무작위)과 initialization(초기화)가 모두 가능한데요.
virtual prompt의 길이만 제공해 이제 random initialization(랜덤 초기화)를 진행해보겠습니다.
# PromptTuningConfig 클래스 사용해 프롬프트 튜닝 Config 생성
peft_config = PromptTuningConfig(
task_type = TaskType.CAUSAL_LM,
prompt_tuning_init = PromptTuningInit.RANDOM,
num_virtual_tokens = 4,
tokenizer_name_or_path = model_name
)
# 지정한 파운데이션 모델과 프롬프트 튜닝 Config 사용해 PeftModel 가져오기
peft_model = get_peft_model(foundation_model, peft_config)
# 학습 가능한 PeftModel의 파라미터 출력
print(peft_model.print_trainable_parameters())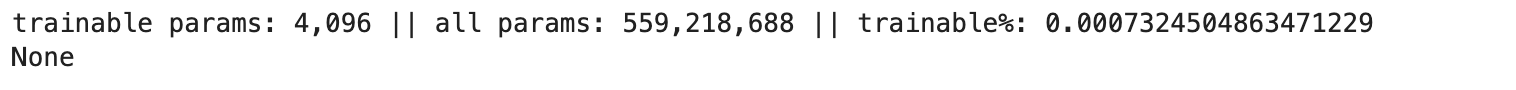
파라미터가 약 5억 5천만개가 있는데요.
그 중 4,096개의 파라미터만 학습을 진행할 예정입니다.(전체의 약 0.0007%)
결과물을 저장할 디렉토리를 생성해주겠습니다.
# 디렉토리 생성
%mkdir/content/working_dir
PEFT를 사용하면 훈련 가능한 파라미터의 수가 급격하게 줄일 수 있는데요.
TrainingArguments를 활용해 파인 튜닝 configuration를 정의해보겠습니다.
# Peft 모델 결과물 저장하기 위한 디렉토리 지정
output_directory = os.path.join("/working_dir", "peft_outputs")
# 작업 디렉토리 존재하지 않는다면, 생성하기
if not os.path.exists("/working_dir"):
os.mkdir("/working_dir")
# output 디렉터토리 존재하지 않는다면, 생성
if not os.path.exists(output_directory):
os.mkdir(output_directory)
# Peft 모델에 대한 훈련 요소 정의
training_args = TrainingArguments(
output_dir = output_directory, # 모델 예측과 체크포인트 저장 위치
no_cuda = True, # GPU 클러스터 사용에 필요
auto_find_batch_size = True, # 자동으로 메모리에 맞는 최적의 batch size 탐색
learning_rate = 3e-2, # 전체 파인튜닝할 때보다 학습률 높게 설정
num_train_epochs = 5 # 전체 파인 튜닝 데이터셋이 몇 번에 나눠서 통과하는 횟수
)
다음으로는 DataCollator를 사용해 훈련을 위해 모델에 전달할 input의 배치 생성을 해보겠습니다.
더 자세하게는 DataCollatorForLanguageModeling를 사용할 건데요.
입력의 크기가 다양할 수 있기 때문에 입력을 배치의 최대 길이로 패딩해서 진행합니다.
# Peft 모델 configuration에서 gradient checkpoint 활성화
peft_model.config.gradient_checkpointing = True
# Peft 모델 학습하기 위한 Trainer 인스턴스 생성
trainer = Trainer(
model = peft_model, # peft 버전 기본 모델인 bloomz-560M 전달
args = training_args, # 위에서 정의한 출력 디렉터리, GPU 사용, 배치 크기 등
train_dataset = train_sample, # 학습 데이터
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm = False) #False: 마스크된 LM 사용하지 않음
)
# 학습 시작
trainer.train()
학습이 잘 되었는데요.
이제 파인튜닝된 모델을 저장해보겠습니다.
# Peft 모델 경로 생성하는 현재 시간 기록
time_now = time.time()
# output_directory와 timestamp 사용해 Peft 모델 저장할 경로 생성
peft_model_path = os.path.join(output_directory, f"peft_model_{time_now}")
# 원하는 경로에 학습된 Peft 모델 저장
trainer.model.save_pretrained(peft_model_path)

output_directory로 지정한 경로에 peft_model_{time_now} 이름의 폴더 아래 3개의 파일이 생성된 걸 확인했습니다.
이제 저장된 모델을 불러와 앞에서 했던 텍스트 생성 질문을 동일하게 해보겠습니다.
# PeftModel 클래스를 사용해 학습된 Peft 모델 불러오기
loaded_model = PeftModel.from_pretrained(
foundation_model, # 프롬프트 튜닝에 사용될 기본 모델
peft_model_path, # Peft 모델이 저장된 위치
is_trainable = False # 불러온 모델은 훈련될 필요 없음
)
모델을 잘 불러왔고요.
불러온 모델에 텍스트 생성을 요청해보겠습니다.
# input_id, attention_mask에 기반해 불러온 Peft 모델을 사용해 텍스트 생성
loaded_model_outputs = loaded_model.generate(
input_ids = input1["input_ids"],
attention_mask = input1["attention_mask"],
max_nex_tokens = 7,
eos_token_id = tokenizer.eos_token_od
)
# 생성된 토큰 id를 사람이 읽을 수 있는 텍스트로 디코딩
decoded_output = tokenizer.batch_decode(loaded_model_outputs, skip_special_tokens = True)
# 디코딩된 결과물 출력
print(decoded_output)
랜덤하게 파인튜닝된 initialized 모델을 text initialization method에 비교해볼텐데요.
변경을 할 부분은 prompt_tuning_init 설정이며, 관련되어 간결한 텍스트 프롬프트를 함께 넣어주겠습니다.
# PromptTuningConfig 클래스 활용해 텍스트 기반 프롬프트 튜닝 configuration 생성
text_peft_config = PromptTuningConfig(
task_type = TaskType.CAUSAL_LM,
prompt_tuning_init = PromptTuningInit.TEXT,
prompt_tuning_init_text = "Generate inspirational quotes", # 모델이 최적의 임베딩 찾을 수 있게 시작점 제공
num_virtual_tokens = 3, # prompt_tuning_init_text 길이에 맞출 필요 없음
tokenizer_name_or_path = model_name
)
# 파운데이션 모델과 텍스트 기반 프롬프트 튜닝 configuration 활용해 PeftModel 불러오기
text_peft_model = get_peft_model(foundation_model, text_peft_config)
# 텍스트 기반 PeftModel의 훈련 가능한 파라미터 수 출력
print(text_peft_model.print_trainable_parameters())
아까보다 훈련 가능한 파라미터의 개수가 1,000개 정도가 줄어들었습니다.
이제 모델 학습을 진행해보겠습니다.
# 텍스트 기반 Peft 모델 학습시키기 위한 Trainer 생성
text_trainer = Trainer(
model = text_peft_model, # 텍스트 기반 Peft 기본 모델
args = training_args, # 위에서 정의한 출력 디렉터리, GPU 사용량, 배치 크기 등
train_dataset = train_sample, # 훈련 데이터셋
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm = False) #False: 마스크된 LM 사용하지 않음
)
# 텍스트 기반 Peft 모델 학습 시작
text_trainer.train()
위에서 학습된 모델을 저장한 것처럼, 동일하게 모델을 저장해 보겠습니다.
# 모델 저장
time_now = time.time()
text_peft_model_path = os.path.join(output_directory, f"text_peft_model_{time_now}")
text_trainer.model.save_pretrained(text_peft_model_path)
# 모델 가져오기
loaded_text_model = PeftModel.from_pretrained(
foundation_model,
text_peft_model_path,
is_trainable = False)
)
# 출력 생성
text_outputs = text_peft_model.generate(
input_ids = input1["input_ids"].
attention_mask = input1["attention_mask"],
max_new_tokens = 7,
eos_token_id = tokenizer.eos_token_id
)
print(tokenizer.batch_decode(text_outputs, skip_special_tokens = True))
허깅페이스에 로그인해, 학습된 모델을 허깅페이스 허브에 올려보겠습니다.
일단, 허깅페이스 로그인이 필요한데요.
2가지 방법으로 진행이 가능합니다.
첫 번째는 터미널에서 토큰 입력인데요.
위의 방법으로 진행했는데, 저는 토큰 입력창이 뜨지 않아서 터미널에서 토큰 입력을 진행했습니다.
pip install huggingface_hub
huggingface-cli login
두 번째, 방법은 다음과 같습니다.
+ 쥬피터랩에서 토큰 입력창 안 나타날 때
참고: Token cannot be pasted in JupyterNotebookin Vscode #752
from huggingface_hub import interpreter_login
interpreter_login()위의 코드로 진행했더니 아래처럼 토큰 입력창이 나왔습니다.
토큰 입력을 해준 뒤, Add token as a git credial?창이 나왔을 때, y를 입력해주면 됩니다.
그러면 'Login successful'이라는 문구가 뜨게 됩니다.


HUGGINGFACE_USERNAME과 token의 경우, huggingface에 로그인 > settings에서 확인할 수 있는데요.
아래 캡쳐 화면 참고해서 진행하시면 됩니다.


# 로그인
hf_username = <HUGGINGFACE_USERNAME>
peft_model_id = f"{hf_username}/bloom_prompt_tuning_{time_now}"
trainer.model.push_to_hub(peft_model_id, use_auth_token = True)
로그인을 해서 model.push_to_hub를 하게 되면 링크와 함께 CommitInfo가 뜨는데요.
링크로 들어가게 되면, 잘 업로된 내역들을 확인할 수 있습니다.

Hugging Face > settings> Models 파트에서도 확인이 가능합니다.
빨간색 박스로 표시된 부분에 방금 업로드한 모델이 표시되는 걸 확인할 수 있습니다.

# 사전 학습된 버전에서 peft model에 관한 configuration 로드
peft_config = PeftConfig.from_pretrained(peft_model_id)
# configuration 활용해 base casual language model 로드하기
foundation_model = AutoModelForCausalLM.from_pretrained(peft_config.base_model_name_or_path)
# 사전 학습된 foundation 모델, Peft 모델 ID로 Peft 모델 생성
peft_random_model = PeftModel.from_pretrained(foundation_model, peft_model_id)
# 'generate' 메서드는 모델에서 텍스트 생성하는데 사용됨
# max_new_tokens는 생성할 새로운 토큰의 최대 개수
# eos_token_id는 end-of-sequence 토큰의 ID로, 생성되는 텍스트의 끝 의미
online_model_outputs = peft_random_model.generate(
input_ids = input1['input_ids'],
attention_mask = input1['attention_mask'],
max_new_tokens = 7,
eos_token_id = tokenizer.eos_token_id
)
# 생성된 token IDs를 사람이 읽을 수 있는 텍스트 형태로 디코딩
# tokenizer의 'batch_decode' 디코딩에 활용됨
# skip_special_tokens = True는 디코딩된 결과물에서 padding이나 eos 같은 특수한 토큰들 제거해주는 역할
decoded_output = tokenizer.batch_decode(online_model_outputs, skip_special_tokens = True)
# 생성된 텍스트 디코딩 된 결과물 출력
print(decoded_output)
Conclusion
결론적으로 프롬프트 튜닝, 그중에서도 특히 PEFT는 언어 모델 성능을 최적화하는데 강력한 프레임워크입니다.
특정 작업이나 프롬프트에 맞게 조정을 할 수 있기 때문인데요.

따라서, 사전 학습된 언어 모델로부터 최대의 효율을 끌어내야 하는 연구자나 실무자들에게 PEFT는 아주 가치 있는 툴입니다.
랜덤 혹은 텍스트 기반 초기화를 하든 PEFT는 유연성(flexibility)과 적응성(adaptability)을 지니고 있기 때문입니다.
Reference
PEFT
🤗 Accelerate integrations
huggingface.co
PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware
Parameter-Efficient Fine-Tuning using 🤗 PEFT
🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware Motivation Large Language Models (LLMs) based on the transformer architecture, like GPT, T5, and BERT have achieved state-of-the-art results in various Natural Lang
huggingface.co
[huggingface] PEFT 소개 및 활용 사
PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware 모델이 점점 커지면서 이제는 일반인들이 사용하고 있는 GPU로도 fine-tuning하기 쉽지 않은 세상이 온 것 같습니다. 그래서 요즘 Pa
discuss.pytorch.kr
Datahunt: 프롬프트(Prompt)란 무엇인가? 정의, 원리, fine tuning(2023.08.14)
프롬프트 (Prompt) 란 무엇인가? - 정의, 원리, fine tuning
프롬프트 (Prompt) 란, 생성형 모델에게 어떤 행동을 해야 하는지 자연어로 설명하고 원하는 결과물을 출력할 수 있도록 하는 방식을 의미합니다. 생성 AI를 사용하는데 필요한 Prompt는 이미 프롬프
www.thedatahunt.com
MARKOVATE: Parameter-Efficient Fine-Tuning(PEFT) of LLMs: A Practical Guide(2023.08.25)
Parameter-Efficient Fine-Tuning (PEFT) of LLMs: A Practical Guide
Unlock the power of Large Language Models with PEFT! 🚀 Dive into our practical guide for efficient tuning & make your models soar
markovate.com
프롬프트 엔지니어링의 8가지 방법
Source: 1. 정적 프롬프트 (static prompts) - 거대 언어 모델의 생성 능력은 다방면으로 활용 가능한 핵심 기능 중 하나 - 거대 언어 모델이 데이터를 활용하고 표현하는 방식을 프롬프트 엔지니어링을
brunch.co.kr
'Tool' 카테고리의 다른 글
| [Lilys AI] AI vs 사람, 누가 더 요약을 잘할까? (1) | 2024.05.02 |
|---|---|
| MLX, 애플에서 발표한 오픈 소스 딥러닝 프레임워크 (1) | 2023.12.26 |
| Inductive Bias (0) | 2023.03.27 |