
2025. 2. 1. 20:53ㆍLecture
이번 글은 2024년 SK AI Summit 2024에서 진행된 강의를 듣고, 정리한 내용입니다.
👉 영상: AI 시대, 최적의 GPU 인프라 선택 방안(On-Premise vs Cloud)

연사자
SK 텔레콤 오상화
강의 내용

✅ AI 시대, GPU가 AI 인프라로써 핵심 경쟁력 되고 있음
✅ 합리적인 GPU 선택 기준에 대한 가이드라인
✅ 엔비디아의 GPU 출시 주기 변경에 따라 AI Serving, Fine-Tuning, Foundation 모델별, GPU 사용 기간과 패턴에 따른 TCO 최소화 방안
✅ SK 텔레콤이 람다와 함께 준비하고 있는 GPUaaS 특장점
1. GPU 시장 동향
✅ 2024년 9월 초, 일론 머스크 XAI에서 122일 만에 10만 장의 H100 배치함
✅ 그 클러스터 만들기도 전에, Grok2라는 LLM 가지고 GPT-4 Turbo 성능 도달함
✅ 10만 장의 H100 어떻게 sourcing 했는지, H100 10만 장 돌리기 위해 원자로 10개만큼의 전기를 어디서 당겨왔는지, 10만 장의 GPU를 어떻게 울트라 인원의 단일 클러스터러 묶었는지
✅ 규모의 경제: GPU 클러스터로(64장) Foundation Model을 From-the-scratch로 만들던지 Fine-tuning으로 오픈 모델을 서빙하든지
GPU 시장 동향

✅ 머신러닝 학습, LLM은 엄청난 수의 행렬 곱 연산
✅ (오른쪽) 엔비디아의 High-End GPU H100 1장으로 50년이 걸릴 일을 1,000장을 한꺼번에 투입하면 18.4일에 끝낼 수 있다는 계산(여러 조건에 따라 달라질 수 있음)
✅ 많은 수의 GPU를 필요한 시기에 바로 사용할 수 있으면, 시간== 돈 절약할 수 있음

1️⃣ 최신 GPU 공급이 부족
✅ 이전 세대 High-End 모델인 A100이 실제 4년간 현역으로 뛰었음
✅ H100이 나왔고, 현재는 H200이 출시되었지만 대부분의 기업에게 많이 공급되지 못한 상황
✅ 빅테크 우선으로 배정되기 때문
2️⃣ GPU 출시 주기가 단축됨
✅ A100은 3년 걸렸는데, H100부터는 1년으로 줄어듬
✅ 주기 단축? 신모델 나올 때마다 2배씩 성능 올라가게 됨
✅ 신모델 누가 빨리 사용해 학습 단축 단축시키고, 많은 수의 파라미터 가진 모델 서빙할 수 있는지가 관건
3️⃣ AI DC
✅ AI DC? GPU 넣을 수 있는 데이터 센터
✅ 기존 대한민국 데이터 센터는 랙 당 평균 12kw로 설계
✅ 글로벌 CESP들이 수용했음
✅ 현재 GPU는 12kW로는 H100 GPU 8장이 꽂혀 있는 HGX 서버를 단 1대밖에 수용하지 못함
✅ 랙 전력밀도, density를 올리지 않으면 케이블링부터 시작해서 여러 문제 생기고, cost overhead 생김. 전기료도 올라가게 됨
✅ Overhead? 어떤 명령어 처리하는데 소비되는 간접적, 추가적인 컴퓨터 자원
4️⃣ 부담 증가
✅ 많은 문제를 해결하기 위해서는 사업자가 많은 수의 GPU를 가지고 경쟁해 규모의 경제 누려야 함
✅ 규모의 경제 가지고 만들어진 사례가 Public Cloud
✅ 하지만 GPU는 워낙 고가이다 보니, overhead 더 줄여야 하는 문제

✅ 규모의 경제 통해, GPU 저렴하게 sourcing 한 다음, 활용률 올리는 방법
✅ AIOps, MLOPs를 빨리 준비해 GPU 효율 올리기
✅ 서비스 개발부터 학습, 학습할 때 스케줄링, 서빙 어떻게 할지 기존에 인하우스에서 개발할지, 만들어놓은 걸 활용할지 결정 필요
Why SK Telecom

1️⃣ 구축, 운영 경험 보유
✅ SK 텔레콤은 한때 구축 시기 세계 50위였던 슈퍼 컴퓨터 클러스터 운영하고 있음(타이탄 클러스터)
✅ Titan Cluster는 A100 전 세계 하이엔드 모델 2,000장으로 이루어져 있음
✅ 타이탄 클러스터를 구축하면서 얻은 know-how를 AI Cloud Manager라는 제품으로 패키징
2️⃣ 최적화된 기술
✅ 12kW 기준으로 구축된 데이터 센터를 44kW 바꾸는 것도 쉬운 작업 아니었음
✅ H100 이후 차세대 모델인 B100의 경우, 전력을 1.5배 요구하고 있음
✅ 그렇게 되면, 직접액체냉각(Direct Liquid Cooling) 쿨런트 파이프가 지나가는 곳에서 서버까지 쿨런트 집어넣는 기술 개발과 PoC 진행 중
[매일경제] SK도 LG도 눈독 들이는 '액체냉각' 뭐길래
SK도 LG도 눈독 들이는 ‘액체냉각’ 뭐길래
‘불덩이’ 엔비디아 칩, 이젠 물로 식힌다
www.mk.co.kr
직접 액체냉각은 서버 내부에 설치한 파이프로 차가운 용액을 지속적으로 흘려 칩 발열 잡는 방식
3️⃣ Lambda와의 협력
✅ CoreWeave(코어위브)라는 GPUaaS(GPU as a Service) GPU만 서비스하는 클라우드 사업자 있음
✅ 그중 SK 텔레콤은 람다에 투자
✅ 람다 아키텍처로 한국의 GPUaaS 만들고 있음(2024년 12월 말 오픈 예정)
👉 [SKT Enterprise] GPUaaS(GPU-as-a-Service)
4️⃣ PENGUIN
✅ GPU critical mass에 따라 방법론 바뀌어야 함
✅ 그게 GPU 4,000장인데, 4,000장 이상의 GPU 구축한 경험 있는 회사
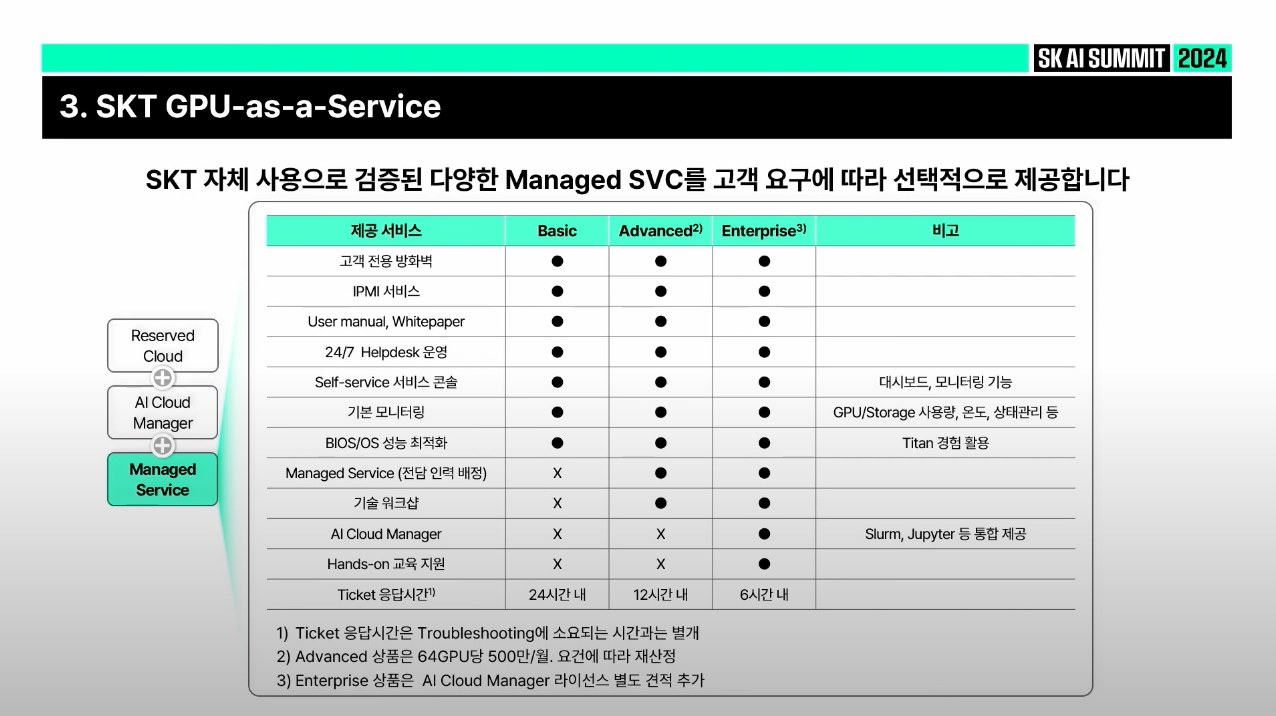
SKT GPU-as-a-Service

✅ 처음에는 Cloud stack 없는 베어메탈(Bare Metal) InfiniBand 클러스터를 고객이 필요한 만큼 서비스 형태로 제공
✅ PCIe타입으로 클라우드화돼서 서비스하는 GPUaaS가 아닌, H100 SXM5 타입으로 고성능의 GPU지원
✅ Storage도 GPU 병렬 학습 스토리지 제공
✅ 고객별로 클러스터 격리하기 때문에 기존 퍼블릭 클라우드에서 생기는 데이터 프라이버시, 거버넌스 문제 상대적으로 해결하기 쉬운 장점
✅ 데이터 Transfer out, 클라우드에서 데이터 밖으로 빼기 위해서는 비용이 필요한데 해당 비용을 책정하지 않음

✅ AI Cloud Manager는 AIOps, LLMOps
✅ (How) GPU Cluster 효율적으로 사용할지 / job scheduling fair 하게 할지 / 사내 모든 조직 계열사들이 사내 GPU 공평하게 이용할지 / 서빙 & 배포 어떻게 할지를 해결할 수 있는 패키지
✅ GPU Cluster 운영은 기존 인프라(Public Cloud, On-Premise IT Infrastructure) 운영 방식과 완전히 다름
✅ 수많은 GPU로 병렬학습하고 있을 때, 1개 GPU에서 fault가 발생하면 체크포인트로 돌아가야 함
✅ 체크포인트로 돌아가 그 GPU가 fault인지, 곧 fault가 될지, 그 GPU가 아닌 코드 문제인지를 식별하기 위해 기존과는 다른 GPU Cluster 운영 인력 필요
✅ Public Cloud의 경우, 종합 IaaS이기 때문에 여러 Overhead가 있음
✅예를 들면, cloud stack에 대한 overhead, 다른 상품과 맞추는데 발생하는 overhead 등
✅ SKT의 GPUaaS는 근간 기술 제공하는 람다와 마찬가지로 Least Price를 아주 낮게 설정하고 필요한 만큼만 사용할 수 있도록
✅ Public Cloud에 사용되는 다량의 GPU 구매하기 위해서는 많은 준비 사항 필요
✅ 한국에서 Global Public Cloud는 H100 같은 하이엔드 GPU 배정되지 않음(우선순위가 떨어지기 때문)

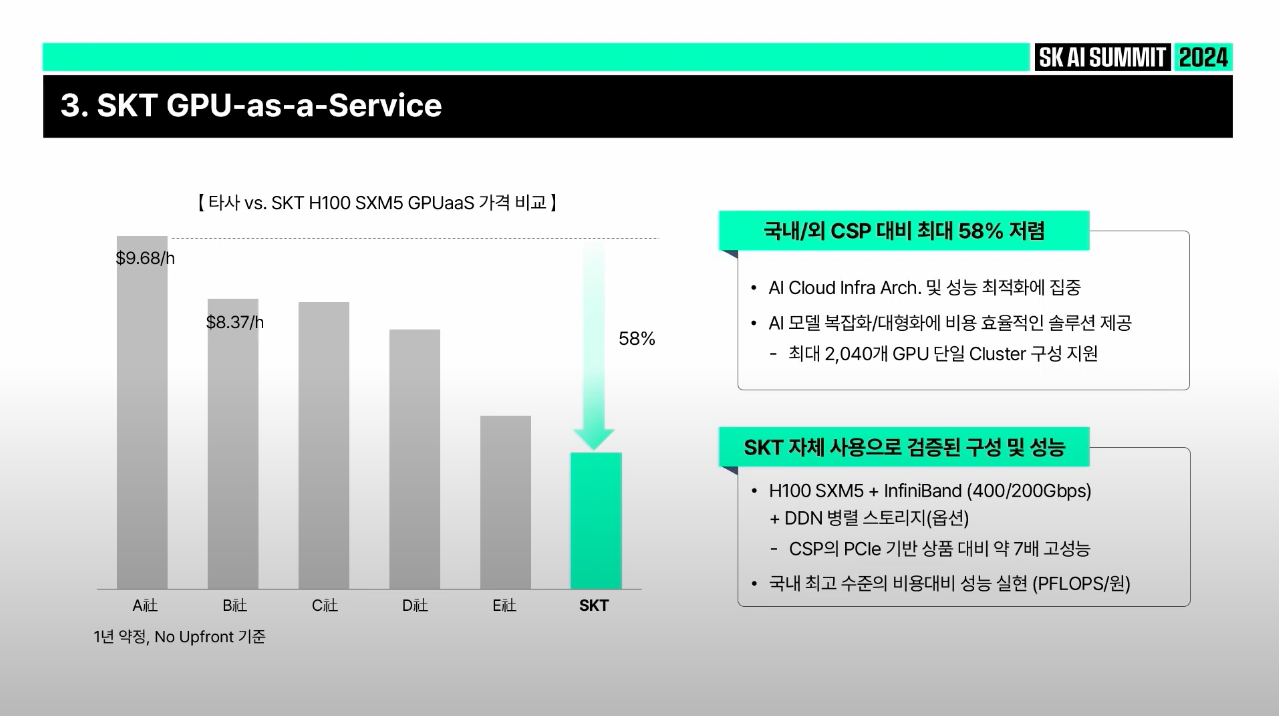
1️⃣ Architecture
✅ PCIe 대신 SMX5에 NVLink로 묶여 있는 H100 GPU를 Infiniband Non-blocking 구성으로 제공
✅ 이건 NVIDIA SuperPOD 구성. 이것보다 나은 포퍼먼스 없음
✅ Infiniband 연결 혹은 이더넷으로 연결된 GPU 학습에 적합한 병렬 스토리지 제공
2️⃣ 추가 비용 없음
✅ Public Cloud의 경우, 1 페타바이트를 밖으로 빼기 위해 DTO(Data Transfer out) 비용이 월 7,000만원 ~ 1억 가까이 발생
✅ GPU 클러스터에서 학습된 데이터를 밖으로 빼거나, 멀티모달에서는 인퍼런스 단계에서조차 DTO 비용이 많이 발생
✅ SK 텔레콤도 MSP(Managed Service Provider)로써 DTO 절감 비용 컨설팅하고 있음
✅ 현재 SK 텔레콤은 DTO 비용을 0원으로 설정해 오픈
3️⃣ 하이브리드 연결 비용 최소화
✅ 고객의 On-Premise, Multi Cloud(여러 Public Cloud 사용)에 불편 없도록 통합 billing으로 제공
SKT AI Cloud Manager

✅ SKT AI Cloud Manager는 개발/학습/배포&추론 모든 workflow 관리
✅ (오른쪽) GPU 성능 효율성 올리는 게 가장 중요. 고가의 GPU의 Util 높이는 게 중요
AI Cloud Manager 역할

✅ (맨 오른쪽) NVIDIA AI Enterprise. NVIDIA의 H100 서버 브랜드인 DGX에 번들링 된 소프트웨어. NVIDIA의 AI Software Platform Ecosystem이 들어 있음
✅ 그중에 LLMOps로서 LLM 만들고, 파인튜닝하는 고객에게 필요한 기능을 최적화해 패키징
✅ (초록색) OEM(HGX Vendor) Dell, HPE(Hewlett Packard Enterprise), 슈퍼마이크로에서 만든 서버들의 클러스터링 되는 부분 이외에 LLMOps에 필요한 스케줄러, 데이터 파이프라인, 서빙까지 컨테이너, 개발환경 쥬피터 등을 모아서 제공
AI Cloud Manager 고객 사용 사례
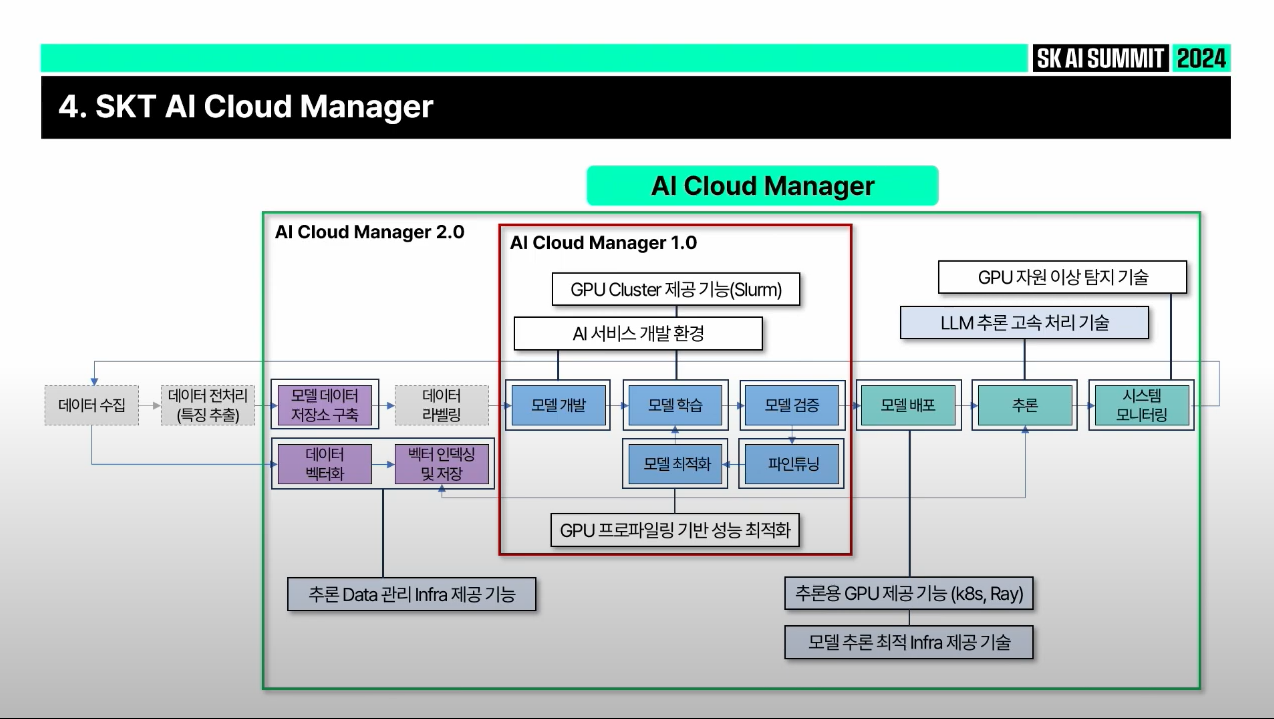
✅ 제1 금융권 여러 계열사들이 서로 공정하게 스케줄링할지, 사용한 만큼 billing 어떻게 할지에 대한 고민 충족시켜야 했음
✅ SKT 내부에서 사용하고 있던 클러스터를 패키징한 것이 1.0(가운데 빨간 박스)
✅ 1.0 버전의 경우, 개발환경과 학습 스케줄링에 초점 맞춤
✅ 2.0 버전(초록색 박스)의 경우, 벡터 임베딩(특히 RAG에 필요), 추론을 위한 모델 배포, pre-define 된 vLLM과 FriendliAI 같이 많이 사용하는 모델에 대해 인퍼런스 성능 예측하고 평가하는 기능까지 포함
사용성 측면

✅ NVIDIA가 인수한 Run:ai에서는 쿠버네티스 기반으로 job scheduling 시작해서 슬럼(slurm)으로 연장하고 있음
✅ 그 이유는 K8S(쿠버네티스)가 업계 표준이고 job submit 때는 유리하지만, 일괄 중지, 일괄 시작, 일괄적으로 명령 내릴 때는 슬럼이 더 우수하기 때문에 슬럼으로 확장
✅ SK Telecom은 2,000장의 A100으로 이루어진 클러스터 관리하기 위해 처음 슬럼으로 스케줄러 만듦
✅ 장점? 쿠버네티스 같이 다양한 기능들, 특히 추론 기능을 슬럼이 지원하기 어렵기 때문에 슬럼에서 시작해서 쿠버네티스로 확장하과 있음
✅ (오른쪽 맨 위 그림) K8S Control Plane 아래에서 슬럼 클러스터는 병렬 학습 위해 존재하고 동시에 여러 GPU 활용해 병렬 학습 어떻게 할지, 학습이 중간에 중지되면 어느 체크포인트로 돌아가고, 어떤 GPU 제거하고 학습할지 등을 슬럼이 담당
✅ (맨 오른쪽 아래 그림) K8S 클러스터에서는 학습 완료하고 검증까지 끝낸 모델을 배포할지, 추론을 실제로 어떻게 돌릴지 관리

✅ GPU 클러스터에서 어떤 지표들을 모니터링하는지
✅ Thread/Core는 IT 인프라를 모니터링할 때 당연히 필요한 부분
✅ CUDA, OpenGL API Trace, cuDNN 등은 SK 텔레콤이 '에이닷 X'라는 파운데이션 모델을 개발, 학습, 서빙하면서 성능 효율 올리기 위해 확인 필요한 지표들
✅ Pre-defined 된 GPU 클러스터에 대한 모니터링 화면, Tool까지 제공
참고
'Lecture' 카테고리의 다른 글
| [SK AI Summit 2024] BTS(Bunker Trading System): 정유사 최초의 AI 챗봇 기반 해상유 마케팅 시스템 (1) | 2025.01.16 |
|---|---|
| [SK AI Summit 2024] AI Together, AI Tomorrow (3) | 2025.01.12 |
| [SK TECH SUMMIT 2023] SKT LLM Enterprise 서비스 2편 (2) | 2024.07.10 |
| [SK TECH SUMMIT 2023] SKT LLM Enterprise 서비스 1편 (4) | 2024.07.10 |
| [랭체인 코리아 밋업 2024 Q2] 테디노트_초보자도 할 수 있는 고급 RAG: 다중 에이전트와 LangGraph 제작 (4) | 2024.07.03 |