
2024. 7. 10. 11:51ㆍLecture
개요
👉 영상: https://www.youtube.com/watch?v=wzYT7kYIDwg
👉 강의 자료: https://sktechsummit.com/sessions/sessionsList.do
SK TECH SUMMIT 2023
AI Everywhere for a better future
sktechsummit.com
연사자
SKT Adapter Team 김성원
강의 내용
내 업무에 딱 맞춘 가벼운 LLM을 만들고 싶다면?
SKT의 LLM을 고객의 필요에 맞게 최적화하여 On-Premise 환경에서 제공하는 Enterprise 서비스를 소개합니다.
문서 요약, 문서 검색, 질의&응답 등 다양한 업무를 비교적 작은 규모의 모델로 지원하기 위해 Fine-Tuning 뿐 아니라 Context 기반 Retrieving 등 다양한 기술을 개발하고 있습니다. 또한 이를 요소화하여 서비스 개발을 가속화하는 LLMOps Framework를 개발하고 있습니다.
기술 전문가와 개발자를 대상으로 세부 기술에 대한 소개와 서비스 개발 과정에서의 경험, 그리고 향후 발전 방향에 대해서 공유하고자 합니다.- Fine-Tuning LLMs
- PEFT(Parameter-Efficient Fine-Tuning)
- LLMOps System 소개 및 Live Demo
1. Fine-Tuning LLMs
왜 LLM을 파인튜닝해야 하는가

✅ 예시는, 주어진 자연어 입력에 대해서 API Function 출력하는 task
✅ 보통 API Function들은 적으면 수십 개, 많으면 수천 개가 되기에 모두 프롬프트에 넣을 수 없음
✅ 반복 실험 통한 최적의 프롬프트 도출하는 노력 필요
✅ 이런 프롬프트는 매 입력마다 들어가야 하기 때문에 토큰의 낭비 발생하고, 이것은 비용과 시간의 낭비로 이어짐
✅ LLM이 가장 그럴듯한 답변을 만들어내겠지만, 이것이 정확한 답변임을 보장할 수 없음
✅ 특히나, API와 같은 새로운 개념을 프롬프트만으로 수용하는 데에는 한계가 있음
Fine-Tuning 후
✅ 원하는 task의 예제들을 모아서 모델을 1번 더 학습해서 우리가 원하는 방법으로 모델이 동작할 수 있게 하는 방식
2. PEFT(Parameter-Efficient Fine-Tuning)

✅ 일반적인 파인튜닝은 LLM의 모든 파라미터들을 업데이트함
✅ PEFT는 일부 추가된 파라미터만 학습하는 형태로 동작
✅ 그래서 Full-fine tuning과 비교해 비용과 시간 절약 가능
✅ 모델 파인튜닝 과정에서 기존에 알고 있던 지식들을 잊어버리게 되는 catastrophic forgetting 현상 완화 가능
PEFT Method 1 - LoRA

✅ 대표적인 PEFT 방식인 LoRA
✅ (오른쪽) X축이 업데이트하는 파라미터 개수 log scale로 나타낸 것
- Full 파인튜닝(파란색)과 비교하면 훨씬 더 적은 파라미터만 학습하는 LoRA가 비슷한 성능 냄
파라미터 업데이트 방식
✅ (왼쪽) 모델 내에 있는 연산 자세히 보기
 |
 |
 |
| ✅ Input "x"가 들어가서 metric W랑 곱해져서 output "h"가 되는 것 | ✅ LoRA는 여기에 Low-Rank(폭이 좁은 메트릭스) 곱 더해줌 ✅ 이때, r이 k와 d에 비해 굉장히 작다면 2개 메트릭스의 파라미터 개수는, 원래 메트릭스 수보다 훨씬 적어지게 될것 |
✅ LoRA는 2개 메트릭스만 업데이트하는 형식으로 학습 진행 |
✅ (오른쪽) X축이 업데이트하는 파라미터 개수 로그스케일로 나타낸 것
- Full 파인튜닝(파란색)과 비교하면 훨씬 더 적은 파라미터만 학습하는 LoRA가 비슷한 성능 냄
PEFT Method 2 - QLoRA

✅ 보통 베이스 모델은 16-bit 데이터 포맷으로 되어 있음
✅ QLoRA는 normal float라는 새로운 데이터 타입 고안해, 베이스 모델을 4-bit로 quantization
✅ LoRA weight 업데이트하는 과정에서 quantization에서 발생했던 손실을 보상하고, 나아가서 원하는 방식으로 모델이 동작하도록 학습시켜 주는 것
✅ 모델 학습할 때 요구되는 메모리를 상당히 줄일 수 있는 게 QLoRA의 핵심
PEFT Method 3 - IA3

✅ (오른쪽) LoRA(보라색 세모)보다도 더 적은 파라미터 개수로 비슷하게 동작하는 모습
파라미터 업데이트 방식
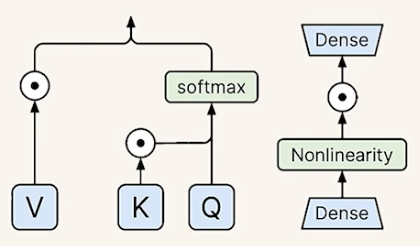 |
 |
✅ 기존 트랜스포머 구성 요소들(value, key, feed-forward network에 있는 iterative action)에 곱해지는 벡터 도입
- (오른쪽) 노란색 박스들: lV, lk, lff
- 곱해지는 벡터들만 학습하는 방식으로 동작
PEFT Method 4 - ToolkenGPT

✅ LLM만으로 정확한 답변 얻기 힘든 상황에서 적용할 수 있는 방식
✅ 외부 툴 사용할 수 있는 방식
✅ (오른쪽) Took 개수 많아질수록, ToolkenGPT 성능이 프롬프팅 방식에 비해 상대적인 성능 이득 높아짐
동작 방식
| 1️⃣ 수학적 연산 필요로 하는 질문 ✅ 간단한 최대공약수 구하는 문제 |
2️⃣ LLM 추론 과정에서 기존과 다른 것? ✅ 일반적인 토큰 뿐만이 아니라, toolken(툴 토큰)도 학습해서 추론 |
 |
 |
| 3️⃣ 만약, next token으로 툴큰이 나온다면, tool 모드로 변경해서 tool 실행할 때 필요한 argument들 추론 | 4️⃣ Tool 실행시킨 후, 결과값 출력 |
 |
 |
✅ API call, 외부 데이터베이스에서 지식 가져오는 등의 형태로 확장될 수 있음
PEFT Methods - Comparison

✅ (왼쪽) 각 PEFT 방식이 어떤 요소/방식 결합하는지 정리
✅ (오른쪽) 실제 2개 내부 모델에 테스트 진행한 결과
각 PEFT 방법 적용할 때, 하이퍼파라미터 완벽하게 최적화하지 않아 최적의 성능 아닐 수 있음
✅ 공통적으로 2가지 모델에서, Full fine-tuning에 비해 PEFT 방식이 훨씬 더 적은 학습시간만으로도 비슷한 성능 혹은 더 나은 성능 보여주고 있음
3. LLMOps System 소개 및 Live Demo
LLMOps System Architecture

✅ 학습한 모델 fine-tuning 하고, fine-tuning 한 모델 text, serving, monitoring까지 하는 LLMOps 시스템 개발 중
✅ Fine-tuning, Deploy 쪽은 많이 구현된 상태
데모영상

✅ Dashboard에서 모델, 데이터셋, training job 목록 나타남
✅ 베이스 모델로 제공하는 모델들(A.X.LLM-S 등) 모델 카드
✅ 학습에 사용되는 데이터셋 preview(메타데이터 표시)
✅ 사용자가 직접 사용할 데이터셋 커스텀해서 올릴 수 있음
✅ training에서 사용했던 base model, 데이터셋, 산출물로 나온 LoRA weight, configuration, tensorboard, log 등을 다운로드할 수 있음
✅ 원하는 base model, 데이터셋, fine-tuning 방식 골라서 학습 시작할 수 있음
✅ 에디터에서 직접 하이퍼파라미터 수정 or 추가할 수 있음
✅ 학습 완료되면 모델 instance 올려서 playground에서 test 진행 가능
✅ 생성 파라미터 조절 가능(temperature, top_k, reputation penalty 등)해 최적화 가능
'Lecture' 카테고리의 다른 글
| [SK AI Summit 2024] AI Together, AI Tomorrow (3) | 2025.01.12 |
|---|---|
| [SK TECH SUMMIT 2023] SKT LLM Enterprise 서비스 2편 (2) | 2024.07.10 |
| [랭체인 코리아 밋업 2024 Q2] 테디노트_초보자도 할 수 있는 고급 RAG: 다중 에이전트와 LangGraph 제작 (4) | 2024.07.03 |
| [랭체인 코리아 밋업 2024 Q2] NaiveRAG부터 Advanced RAG 톺아보기(with code) (2) | 2024.07.02 |
| [SK TECH SUMMIT 2023] LLM의 미래 - KGPT(AI KMS)와 sLLM 소개 (0) | 2024.05.09 |