
2024. 7. 3. 17:42ㆍLecture
제 RAG 경험은 LangGraph 경험하기 전과 후로 나뉩니다
👉 영상: https://www.youtube.com/live/MM9x42gTBag
👉 강의 자료: https://aifactory.space/task/4239/discussion/1587

연사자
테디노트(이경록)

강의 내용
- LangGraph는 어떤 프레임워크일까?
- State, Node, Edge, Conditional Edge
- 간단한 사례로 살펴보는 LangGraph 동작
- Self-RAG: Retrieval 관련성 평가로 Hallucination 줄이기
- Corrective RAG: 질문을 더 섬세하게
- 부족한 내용은 검색: RAG + Additional Search on Web
LangGraph
탄생 배경
1️⃣ LLM이 생성한 답변이 Hallucination이 아닐까?
2️⃣ RAG 적용해 받은 답변이 문서에는 없는 "사전지식"으로 답변한건 아닐까?
3️⃣ 문서 검색에서 원하는 내용 없을 경우
- 인터넷 혹은 논문에서 부족한 정보 검색해 지식 보강할 수 없을까?
RAG 개발 단계 고민 사례(1)
✅ 일반 RAG 수행했을 때, 흔히 볼 수 있는 상황
- 문서 내 질문에 대한 답변 존재하지 않는 경우, "문서에 나와있지 않아 답변을 생성하지 못함"

RAG 개발 단계 고민 사례(2)
✅ 부족한 정보를 Web 검색해 문서에 추가하는 로직 추가해보기
- 문제1 정보 검색 과정을 언제 해야 하는가
- 문제2 검색된 정보가 정확한 정보인지 어떻게 판단하는가

RAG 개발 단계 고민 사례(3)
✅ 만약 검색결과에 잘못된 정보가 포함되거나 혹은 검색 결과에 없다면?
- 삼성전자가 아닌 삼성SDS의 매출액을 검색함

RAG 개발 단계 고민 사례(4)
✅ 잘못된 검색결과가 결국 Hallucination으로 이어진다면?

RAG 개발 단계 고민 사례(5)
✅ 검색 제대로 나올 때까지 반복해 검색 해볼까?(반복문)
- 무한히 제대로 된 결과가 안 나올 경우, 토큰 샤용량 폭증
✅ Hallucination을 방지하는 LLM 추가해야 하나?
💡 결국
✅ 코드가 점점 길어지고 복잡해짐
✅ LLM의 일관되지 않은 답변이 마치 나비효과로 이어져 답변 품질저하로 이어짐

Conventional RAG 문제점
RAG 파이프라인 보통 8단계로 잡음(문서 로드, 분할, 임베딩, 저장, 질문 들어오면 검색, 프롬프트 넣기 등)
✅ 사전에 정의된 데이터 소싱(PDF, DB, Table 등) 자원
✅ 사전에 정의된 Fixed Size Chunk
✅ 사전에 정의된 Query 입력
✅ 사전에 정의된 검색 빙법
✅ 신뢰하기 어려운 LLM 혹은 Agent
✅ 고정된 프롬프트 형식
✅ LLM 답변 결과에 대한 문서와의 관련성/신뢰성
➡️ 사전에 고정되어야 하는 부분들이 많음
 |
 |
문제 정리

✅ Document Loader(데이터 로드) -> Answer(답변) RAG 파이프라인이 단방향 구조이기 때문
✅ 모든 단계를 1번에 다 잘해야 함
✅ 이전 단계로 되돌아가기 어려움
- 이전 과정의 결과물 수정하기 어려움
해결
✅ 흐름을 추가
- 4번 단계에서 잘못된 걸 확인하면, 3번 단계로 되돌아가 수정하고 4번으로 돌아와 스스로 문제해결할 수 있도록
LangGraph 제안
✅ 각 세부과정을 노드(Node)라고 정의
- RAG의 8단계를 노드로 패키징
✅ 이전 노드 > 다음 노드: 엣지(Edge) 연결
- 엣지는 방향성 갖고 있음
✅ 조건부 엣지 통해 분기 처리
- 노드와 엣지 연결하는 구조 가짐으로써 단방향이 아니라
- store에서 edge를 split으로 연결해 되돌아갈 수 있음
➡️ RAG 파이프라인을 보다 유연하게 설계
✅ 평가자 & Query Transform 추가
✅ 평가자 & Query Transform 추가
- 사용자 질문 들어오면, 초기 검색 진행
- 문서 검색 결과에 원하는 정보 있으면, LLM이 답변 생성으로 넘김
- 문서 검색 결과에 원하는 정보 없으면, LLM이 평가자(Evaluator)가 되어 질문 재작성 요청
- Query를 Rewrite하는 Query Transformation해서 질문 다시 바꿔서 넣어보기
- 질문 바뀌었기에 검색된 문서 내용도 변경됨
- 변경된 문서 검색 내용 다시 평가

✅ 추가 검색기 통해 문맥(context) 보강
- 생성된 답변에 대해 사람이 모두 hallucination 여부 확인하기 힘듬
- LLM Evaluator를 통해 답변 새엇ㅇ된 결과에 대해서 평가
- 평가했는데, 검색된 문서가 잘못되었다면 질문 재작성 과정으로 이동
- 평가했는데, 문서에는 없는 정보가 요청되었다면 "웹 검색" 노드로 신호 보내는 것
- 웹 검색해서 내용 보강해서 다시 평가 요청

✅ 문서- 답변 간 관련성 여부 판단하는 평가자2 추가해 검증
- 문서 검색된 결과를 평가할 수도 있고, 답변 생성된 결과를 평가할 수도 있음
- Hallucination 발생은 어느 정도 감안해야 하지만, 평가자를 둠으로써 확률적으로 hallucination 줄일 수 있음
➡️ 고전적인 단방향 구조에서 유연한 흐름(뒤로 가는 or 옆으로 빠지는) 만들 수 있음

LangGraph로 구현한 예시
✅ 유연한 흐름 가지는 LangGraph 예시

✅ Node(노드), Edge(엣지), State(상태 관리) 통해 LLM 활용한 워크폴로우에 순환(Cycle) 연산 기능 추가해 손쉽게 흐름 제어
✅ RAG 파이프라인의 세부 단계별 흐름제어가 가능
✅ Conditional Edge: 조건부(if, elif, else와 같은..) 흐름 제어
✅ Human-in-the-loop: 필요시 중간 개입해 다음 단계 결정
✅ Checkpointer: 과거 실행 과정에 대한 "수정" & "리플레이" 기능

주요 용어
✅ Node(노드): 어떤 작업(task) 수행할지 정의
✅ Edge(엣지): 다음으로 실행할 동작 정의
✅ State(상태); 현재 상태 값을 저장 및 전달하는데 활용
✅ Conditional Edge(조건부 엣지): 조건에 따라 분기 처리
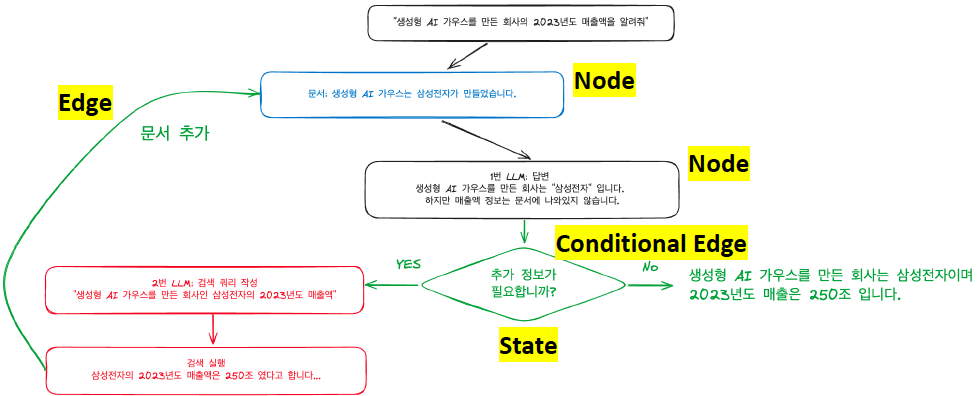
상태(State)
✅ 노드와 노드 간 정보 전달할 때, 상태(State) 객체에 담아 전달
- TypedDict: 일반 파이썬 dict에 타입힌팅 추가한 개념. 쉽게 딕셔너리(key-value)
- 모든 값 채우지 않아도 됨
- 새로운 노드에서 값 덮어쓰기(Overwrite) 방식으로 채움

노드별 상태 값 변화
✅ 각 노드에서 새롭게 업데이트 하는 값은 기존 Key 값 덮어쓰는 방식
✅ 노드에서 필요한 상태 값 조회하여 동작에 활용할 수 있음
✅ 노드4에서 노드1에서 반영된 llm 값이 그대로 상태 전달되어 조회 가능

RAG 사례
✅ 노드4에서 "문서"에 대하여 답변 관련성 점수 부여
✅ score가 "BAD"인 경우 (선택할 수 있는 행동 3가지)
- 노드1: 질문 재작성 요청
- 노드2: 문서 다시 검색/검색 통한 정보 보완
- 노드3: 답변 재작성 요청

노드1: 질문 재작성 요청
✅ 질문 재작성 요청 받은 후, 질문2로 갱신
✅ 문서, 답변도 갱신되어 score가 "Good"이 됨
✅ 노드 4 -> 노드1 Query Transform 흐름 연결만해줌으로써 hallucination 해소

노드2: 문서 검색 재요청
✅ 다른 리트리버 사용해 문서 검색 다시 진행

노드3: 답변 재생성 요청
✅ GPT 말고 Claude or Local 모델 사용해서 답변 다시 생성
✅ 대단히 복잡한 알고리즘이 추가되는게 아니라 Edge만 연결해줬더니 알아서 동작

노드(Node) & 엣지(Edge)
노드(Node)
✅ 함수로 정의
✅ 입력인자: 상태(State) 객체
✅ 반환(return)
- 대부분 상태(State) 객체
- Context key만 업데이트 해준 모습
- Conditional Edge의 경우 다를 수 있음
✅ 중간 동작 위한 코드 구현
- Python 코드, API 호출, SQL DB 검색, invoke 등
- 각 단계별로 함수만 노드화도 가능

Graph 생성 후 노드 추가
✅ 이전에 정의한 함수를 Graph에 추가
✅ add_node("노드이름", 함수)

from langchain.graph import END, StateGraph
from langchain.checkpoint.memory import MemorySaver
#langgraph.graph에서 StateGraph와 END 가져오기
workflow = StateGraph(GraphState)
# 노드 정의
workflow.add_node("retriever", retrieve_document) # 에이전트 노드 추가
workflow.add_node("llm_answer", llm_answer) # 정보 검색 노드 추가# 문서에서 검색해 관련성 있는 문서 찾기
def retrieve_document(state: GraphState) -> GraphState:
# Question에 대한 문서 검색을 retriver로 수행
retrived_docs = pdf_retriver.invoke(state["question"])
# 검색된 문서를 context 키에 저장
return GraphState(context = format_docs(retrived_docs))
# Chain 사용해 답변 생성
def llm_answer(state: GraphState) -> GraphState:
return GraphState(
answer = pdf_chain.invoie({"question": state["question"], "context": state["context"]}))엣지(Edge)
✅ 노드에서 노드간의 연결
✅ add_edge("노드이름", "노드이름")
- from > to

# 각 노드 연결
workflow.add_edge("retrieve", "llm_answer") # 검색 -> 답변
workflow.add_edge("llm_answer", "relevance_check") # 답번 -> 관련성 체크조건부 엣지(Conditional Edge)
✅ 노드에 조건부 엣지 추가해 분기 수행할 수 있음
✅ add_conditional_edges("노드이름", 조건부 판단 함수, dict로 다음 단계 결정)
흐름
✅ "relevance_check" 노드에서 나온 결과를 is_relevant 함수에 입력
✅ 반환된 값은 "grounded", "notGrounded", "notSure" 중 하나
- value에 해당하는 값이 END면 Graph 실행 종료
- "llm_answer"와 같이 노드이름이면 해당 노드로 연결
# 조건부 엣지 추가
workflow.add_conditional_edges(
"relevance_check", # 관련성 체크 노드에서 나온 결과를 is_relevant 함수에 전달
is_relevant.
{
"grounded": END, # 관련성 있으면 종료(hallucination❌)
"notGrounded": "llm_answer", # 관련성 없으면 다시 답변 생성
"notSure": "llm_answer", # 관련성 체크 결과가 모호하다면 다시 답변 생성
},
)시작점 지정
✅ set_entry_point("노드이름")
✅ 지정한 시작점부터 Graph가 시작

# 시작점 설정
workflow.set_entry_point("retrieve")그래프 생성 및 시각화
체크포인터(memory)
✅ Checkpointer: 각 노드간 실행결과 추적하기 위한 메모리(대화에 대한 기록과 유사 개념)
✅ 체크포인터 활용해 특정 시점(Snapshot)으로 되돌리기 기능도 가능
✅ compile(checkpointer = memory) 지정해 그래프 생성
#기록 위한 메모리 저장서 설정
memory = MemorySaver()
#그래프 컴파일
app = workflow.compile(checkpointer = memory)그래프 시각화
✅ get_graph(xray = True).draw_mermaid_png()
- 생성한 그래프 시각화
- relevance_check의 경우, 업스테이지의 "groundchecker"? or llm으로 만들 수 있음
display(
Image(app.get_graph(xray = True).draw_mermaid_png())
) # 실행 가능한 객체의 그래프를 mermaid 형식의 PNG로 그려서 표기
실행 및 결과 확인
그래프 실행
✅ RunnableConfig
- recursion_limit: 최대 노드 실행 개수 지정(13인 경우: 총 13개의 노드까지 실행)
- thread_id: 그래프 실행 아이디 기록하고, 추후 추적 목적으로 활용
✅ 상태(State)로 시작
- 여기서 "question"에 질문만 입력하고 상태를 첫 번재 노드에게 전달
✅ invoke(상태, config) 전달해 실행
from langchain_core.runnable import RunnableConfig
#recursion_limit: 최대 반복 횟수, thread_id: 실행 ID(구분용)
config = RunnableConfig(recursion_limit = 13, configurable = {"thread_id": "SELF-RAG"})
#GraphState 객체 활용
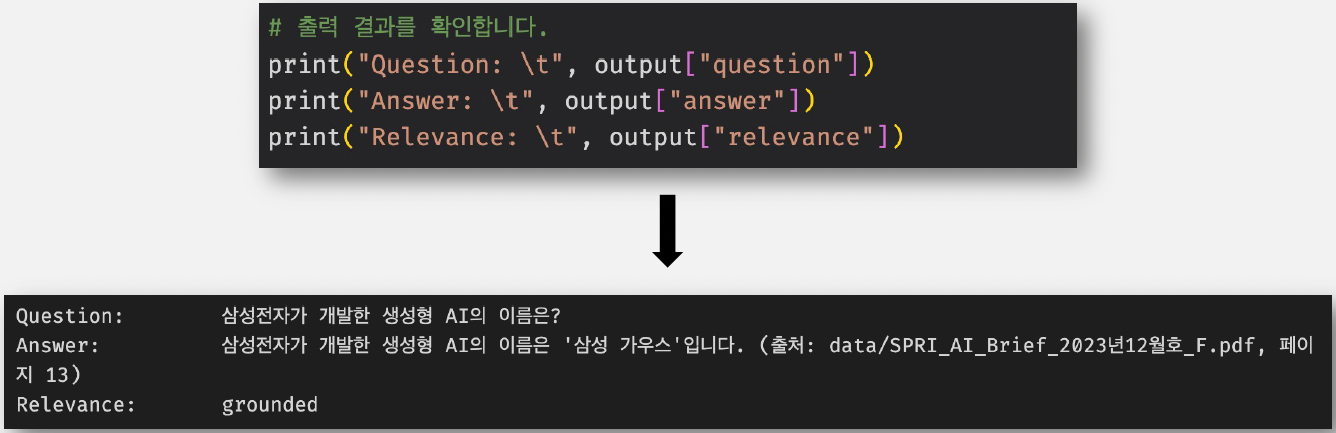
inputs = GraphState(question = "삼성전자가 개발한 생성형 AI의 이름은?")
output = app.invoke(inputs, config = config)
#출력 결과 확인
print("Question: \t", output["question"])
print("Answer: \t", output["answer"])
print("Relevance: \t", output["relevance"])결과 확인
✅ 출력된 결과로 최종 확인
✅ 출력 결과 역시 상태(State)에 담겨 있음
- 출처 나오고, Relevance 상태 나옴
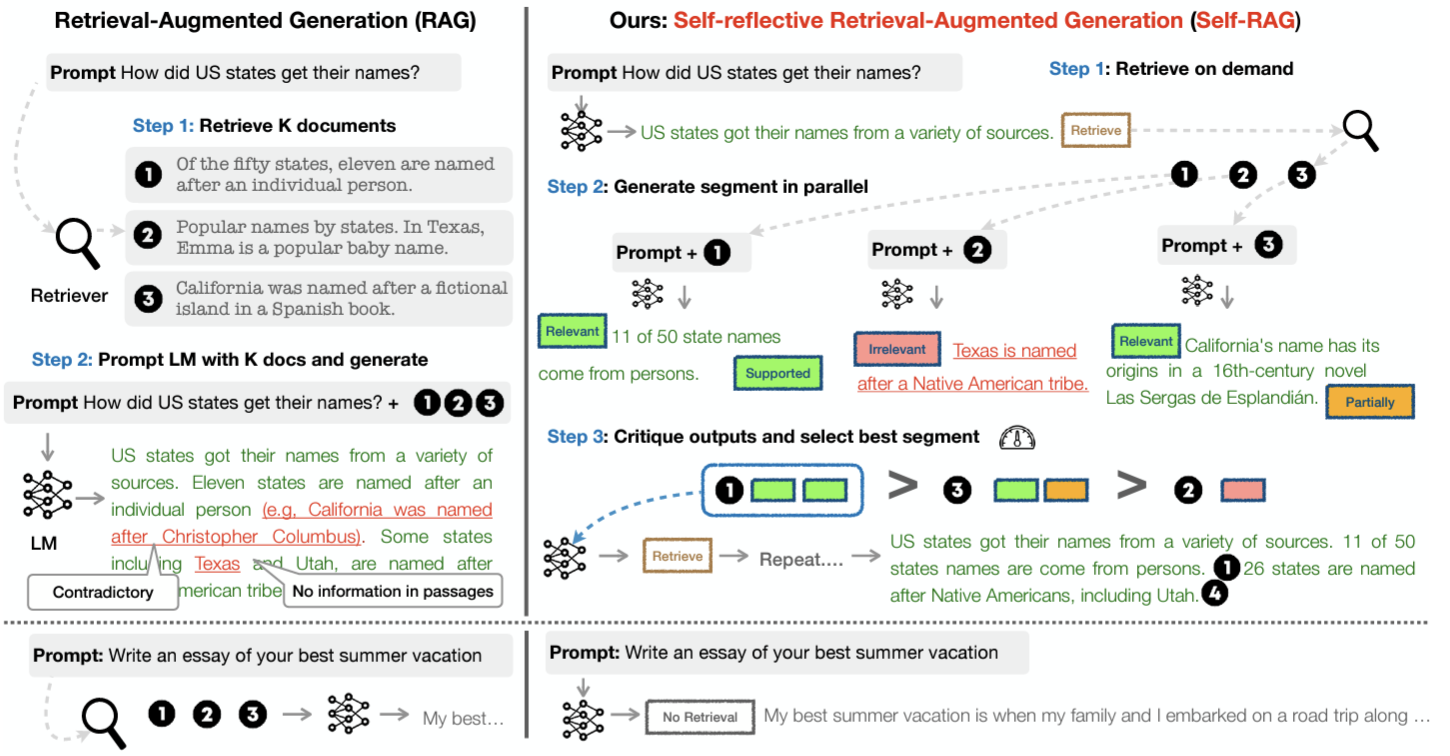
Self-RAG
👉 논문: SELF-RAG: Learning to Retrieve, Geneate and Critique through Self-Reflection
배경
✅ Fixed Size Retrieval: 좋든 싫든 정해진 크기만큼 검색해 가져오기 때문에, 검색에 노이즈 있을 수 있음
- 사전에 chunk_size 지정하는 것
✅ 무분별하게 주입되는 검색으로 문서내 다른 정보 참고하거나, 제대로 된 답변 나오지 않는 경우 있음
✅ 검색된 정보의 정확성 신뢰할 수 없음
제안
✅ 선택적 Retrieval 도입(필요한 만큼만 Retrieve)
- 필요한 정보만 검색해서 관련성 있는(초록색 박스)만 사용, 관련성 없으면(핑크색 박스) 사용X, 절반 정도 관련성(노란색 박스)은 가져감
- 가져온 초록색 + 노란색 내용들로 final answer 잘 조합
✅ Retrieval로부터 답변 도출
✅ 도출된 답변과 Retrieval Passage 간 관련성 체크
관련성 체크 흐름
✅ 참고 코드: 02-langgraph-groudcheck.ipynb
✅ relevance_check 하는 방법
- llm_answer와 검색된 문서를 같이 넣어준 후, 역방향으로 답변을 문서에서 찾게끔 함
- 답변이 문서내에 있으면? Relevance, 문서내에 없으면? Relevance하지 않다라고 판단
➡️ 확실히 문서에서 검색된 것인지 확인해볼 수 있음
✅ 코드 1줄로 흐름 제어
- relevance_check > llm_answer
- relevance_check > retrieve
 |
 |
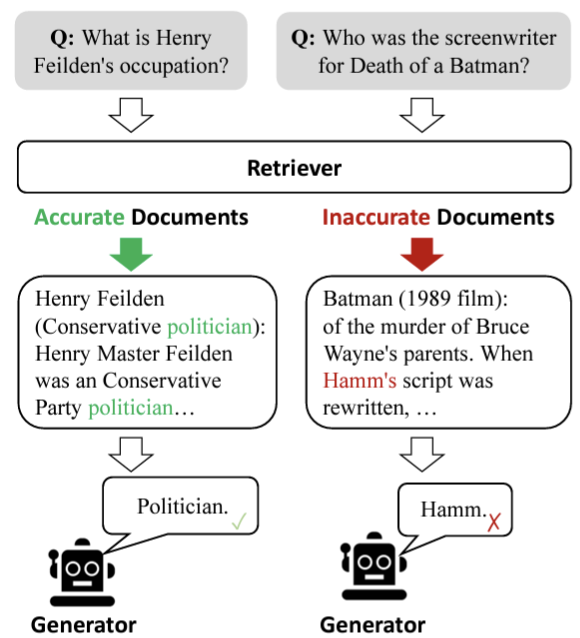
Corrective-RAG(C-RAG)
👉 논문: Corrective Retrieval Augmented Generation
배경
✅ 어떤 사용자 질문이 들어올지 모름
✅ RAG 답변 결과는 검색된 문서의 관련성에 크게 의존적
✅ 따라서, 검색 잘못된 경우 답변에 대한 품질 우려가 큼
제안
✅ 사용자 입력 쿼리(query)에 대하여 검색된 문서의 품질 평가
- 품질 평가 통과되면 그대로 가는 것
- 만약, 잘못된 답변 or 잘못된 문서 검색이면 query 수정
✅ 검색된 결과가 사용자 입력 쿼리와 관련성 높도록 쿼리 수정(Corrective)
- 다시 되돌아가는 과정 있기 때문에, conventional rag 방식으로는 구현하기 까다로움
✅ 이전의 Relevance Check 수행 후, 결과에 따라 쿼리 조정(Corrective)
- notGrounded, notSure의 경우, rewrite 진행
✅ 재작성된 쿼리로 다시 문서 검색 수행

Retrieve and Search
✅ retrieve -> llm_answer -> relevance_check에서 관련성 체크
✅ 검색된 문서에 답변에 필요한 정보 부족한 경우
- "웹 검색" 위한 쿼리 재작성
✅ "웹 검색"으로 보충된 정보로 답변 도출 시도
✅ 새로운 답변으로 관련성 체크 후 재조정/종료 진행
__start__: 질문 입력
- "생성형 AI 가우스를 만든 회사의 2023년도 매출액은 얼마인가요?"
- 생성형 AI 만든 정보? 문서 + 매출액 정보? 웹 검색"해서 답변 생성

retrieve: PDF 문서에 대한 검색 수행
- "생성형 AI 가우스 만든 회사의 2023년도 매출액은 얼마인가요"

llm_answer: 문서 기반 답변 도출(GPT)
# 답변
생성형 AI '가우스'를 만든 회사는 삼성전자입니다.
그러나 제공된 문맥에서는 삼성전자의 2023년도 매출액에 대한 정보는 언급되어 있지 않습니다.
따라서 삼성전자의 2023년도 매출액에 대한 정보를 제공할 수 없습니다.relevance_check: 관련성/유효성 체크
# 답변
생성형 AI '가우스'를 만든 회사는 삼성전자입니다.
그러나 제공된 문맥에서는 삼성전자의 2023년도 매출액에 대한 정보는 언급되어 있지 않습니다.
따라서 삼성전자의 2023년도 매출액에 대한 정보를 제공할 수 없습니다.
# 이전 답변의 관련성/유효성 체크
"notGrounded"rewrite: 추가정보 검색 위한 쿼리 재작성
# rewrite: 부족한 정보에 대해서만 쿼리 재작성
"Rewrite the question to get additional information to get the answer"
# 결과
"삼성전자의 2023년도 매출액은 얼마인가요?"search_on_web: 재작성된 쿼리로 검색 수행
# 재작성된 쿼리
"삼성전자의 2023년도 매출액은 얼마인가요?"
llm_answer: 문서 기반 답변 도출(GPT)
✅ 웹 검색 결과를 llm_answer에 포함
relevance_check: 관련성/유효성 체크
# 답변
삼성전자의 2023년도 매출액은 258.94조원입니다.
(출처: https://news.samsung.com/kr/삼성전자-2023년-4분기-실적-발표)
# 이전 답변의 관련성/유효성 체크
"grounded"__end__: 종료
# 질문
"생성형 AI 가우스를 만든 회사의 2023년도 매출액은 얼마인가요?"
# 답변1
삼성전자의 2023년도 매출액은 258.94조원입니다.
# 답변2
생성형 AI "가우스"를 만든 회사는 삼성전자이며, 2023년도 매출액은 258.94조원입니다.랭스미스 추적
https://smith.langchain.com/public/ce7b4ea8-df34-4bb6-850e-afc8d12e75e6/r
LangSmith
smith.langchain.com

간단한 코드 구현
from typing import TypedDict, Annotated, Sequence
import operator
# State 정의
class GraphState(TypedDict):
context: Annotated[Sequence[Document], operator.add]
answer: Annotated[Sequence[Document], operator.add]
question: Annotated[str, operator.add]
sql_query: Annotated[str, operator.add]
binary_score: Annotated[str, operator.add]
'Lecture' 카테고리의 다른 글
| [SK TECH SUMMIT 2023] SKT LLM Enterprise 서비스 2편 (1) | 2024.07.10 |
|---|---|
| [SK TECH SUMMIT 2023] SKT LLM Enterprise 서비스 1편 (2) | 2024.07.10 |
| [랭체인 코리아 밋업 2024 Q2] NaiveRAG부터 Advanced RAG 톺아보기(with code) (0) | 2024.07.02 |
| [SK TECH SUMMIT 2023] LLM의 미래 - KGPT(AI KMS)와 sLLM 소개 (0) | 2024.05.09 |
| [SK TECH SUMMIT 2023] RAG를 위한 Retriever 전략 (0) | 2024.05.05 |