
2024. 9. 12. 22:01ㆍLLM
개요
해당 글은 OpenAI Platform documentation에 있는 항목을 번역해오며 첨언한 글입니다.
👉 출처: Optimizing LLMs for accuracy
LLM 활용시, 정확도 & 일관성 2마리 🐰 잡기
✅ OpenAI에서 많은 스타트업 & 대기업 개발자와 작업해 본 결과, LLM 최적화는 다음과 같은 이유들로 어려움
- 정확도 최적화 어떻게 시작해야 하는지
- 언제, 어떤 최적화 방법 사용할 것인지
- 배포에 적합한 정확도 수준은 어느 정도인지
✅ 이 글에서는 LLM의 정확도와 동작 위한 최적화 방법에 대한 mental 모델 제공
Mental Model
👉 참고: AI Design Guide #3. 멘탈모델
AI Design Guide #3. 멘탈모델
인공지능 디자인하기 5단계 중 3단계 (멘탈모델) | PAIR의 구글의 AI 디자인 가이드북을 5개의 챕터로 조금 다듬어 번역/공유해보고자 한다.1. 사용자 니즈2. 데이터 3. 멘탈모델4. 신뢰와 피드백5.
brunch.co.kr
- 인공지능은 사용자 개인별로 나오는 결과물이 불명확한, 혹은 해석하고 이해하기 어려운 서비스
- 사람들의 사고와 배경에 대한 하나의 모델
✅ prompt engineering, RAG, fine-tuning 등의 방법들을 언제, 어떻게 사용해야 하는지 확인
✅ 배포하기에 '충분히 좋은(good enough)' 정확도?
- LLM 정확도 논의 전, LLM의 실패로 인한 비용과 성공으로 인한 비용 절감 또는 수익에 대한 대략적인 기준이 있어야 함
LLM 문맥 최적화
✅ 많은 최적화 방법 가이드에서는, 최적화를 단순한 선형적 흐름으로 설명
- 프롬프트 엔지니어링으로 시작해, 검색 증강 생성(이하 RAG)을 한 후, 미세 조정 하는 방식
✅ 그러나, 실제로는 그렇지 않은 경우 많기에 상황별에 맞는 최적화 방법 필요
✅ LLM 최적화 매트릭스를 다음과 같이 표현할 수 있음

✅ 일반적인 LLM 최적화는 왼쪽 하단 프롬프트 엔지니어링에서 시작해 테스트, 학습 및 평가 통해 baseline 확보
✅ baseline 예제들 리뷰하고, 왜 부정확한지 평가한 후, 아래 축 중에 하나를 선택하는 방식
- 컨텍스트 최적화: 이 축은 응답 정확도 최대화함
- 1) 학습 데이터셋에 포함되지 않아 모델이 컨텍스트 지식 부족하거나
- 2) 지식이 오래되었거나
- 3) 독점 정보(영업 비밀)에 대한 지식 필요하거나
- LLM 최적화: 이 축은 동작의 일관성 최대화함
- 1) 모델이 잘못된 형식에 일관성 없는 결과 생성하거나
- 2) 어조나 말투가 올바르지 않거나
- 3) 추론이 일관적이지 않을 때
✅ 실제로는 다음의 최적화 단계 많이 밟음
- 평가 -> 최적화 방법 가설 세우기 -> 가설 적용 -> 평가 -> 다음 단계 위해 재평가
✅ 다음 메트릭스는 매우 일반적인 최적화 흐름의 예시

✅ 위의 매트릭스 예시에서는 다음의 과정을 거침
- 프롬프트로 시작한 다음, 성능 평가
- 답변 결과의 일관성을 보장하는 정적인 few-shot 예제 추가
- 검색 단계 추가해 사용자의 질문에 따라 동적으로 few-shot 예제 가져오도록 함. 각 입력에 대한 관련 컨텍스트 보장해 성능 향상시킴
- 50개 이상의 예제로 구성된 데이터셋 준비하고 모델을 파인토닝해 일관성 향상
- 검색 단계 튜닝하고 사실 확인 단계 추가해 할루시네이션 찾아내 정확도 높이기
- 향상된 RAG 입력이 포함된 새로운 훈련 예제에 대해 파인 튜닝된 모델 재학습
✅ 이는 실제 어려운 비즈니스 문제를 해결하는 일반적인 최적화 파이프라인
✅ 관련성이 높은 컨텍스트가 더 필요한지 or 모델의 일관된 종작이 필요한지 여부 결정하는데 도움이 됨
✅ 일단 결정이 되면, 최적화를 위해 어떤 단계로 나아가야 하는지 알 수 있음
✅ 만들어진 멘탈 모델을 토대로, 모든 영역에서 어떤 방법 취해야 하는지 각 상태별로 알아보기
프롬프트 엔지니어링
✅ 프롬프트 엔지니어링은 LLM 최적화할 때 가장 접근하기 쉬운 방법
✅ zero-shot 방법으로 배포 수준의 정확성, 일관성 도달해야하는 요약, 번역, 코드 생성 등에 유일한 방법이기 때문
✅ 왜냐하면, use case에서의 정확도가 어떤 걸 의미하는지 정의해야 함
✅ 가장 기본적인 수준의 입력값으로 결과가 예상과 일치하는지 여부를 판단할 수 있어야 함
✅ 결과가 원하는 결과와 일치하지 않는다면, 최적화 위해 어떤 방법을 사용해야 하는지 알 수 잇음
✅ 원하는 결과를 출력하기 위해서는, 항상 간단한 프롬프트와 예상 출력을 염두에 두고 시작해 컨텍스트, instruction, 예제를 추가해 프롬프트를 최적화하는 방향으로 나아가야 함
최적화
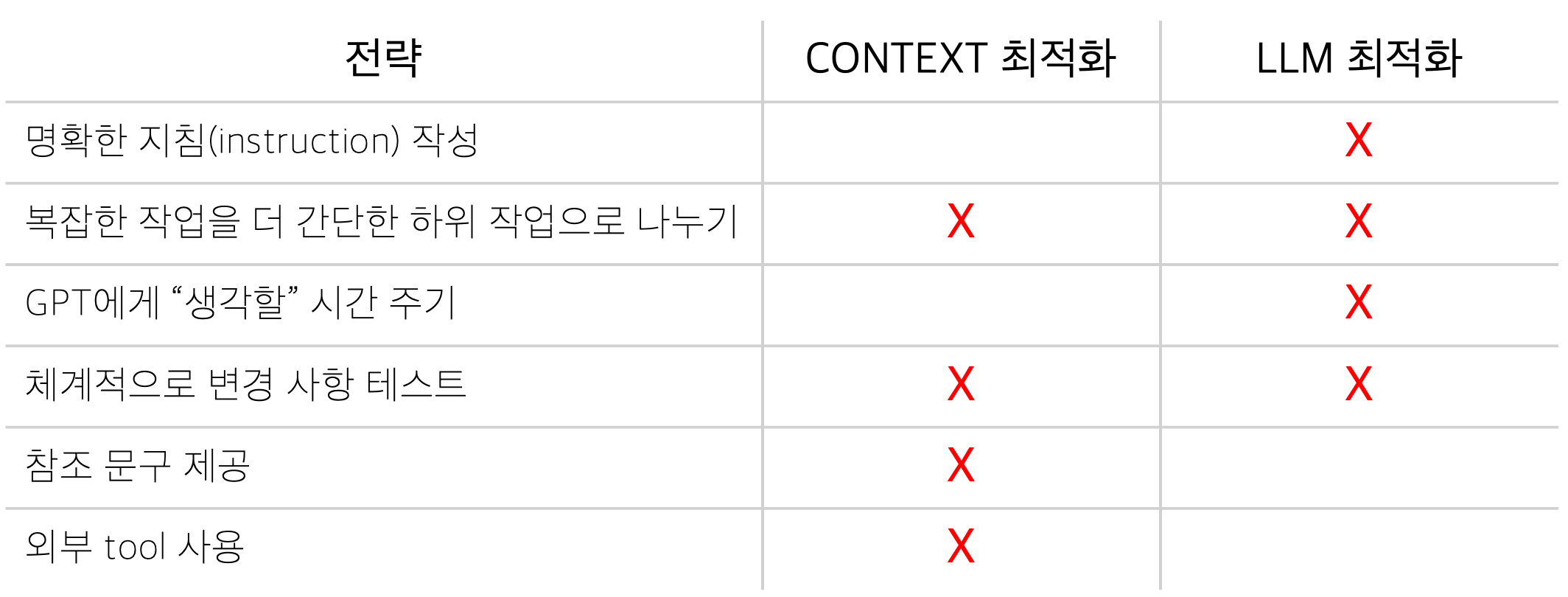
✅ 프롬프트 최적화를 위해 OpenAI API 문서 Prompt Engineering guide에 있는 전략 활용
✅ 각 전략은 켄텍스트, LLM 또는 2가지 모두 튜닝하는데 도움이 됨
✅ gpt-4-turbo 모델 활용, 실제 예제 통해 테스트해보기
✅ 아이슬란드어 문장을 교정하며 어떻게 동작하는지 살펴보기
언어 교정 위한 프롬프트 엔지니어링
✅ 아이슬란드 오류 코퍼스(Icelandic Errors Corpus)에는 아이슬란드어 오류 문장과, 해당 문장의 수정 버전이 조합되어 있음
✅ 기본 GPT-4 모델 사용해 언어 교정을 하교, 다양한 최적화 기법을 적용해 모델 성능 개선하는 방법 살펴보기
✅ 아이슬란드어 문장이 주어지면, 모델이 이 문장을 교정해서 반환하기를 희마앟ㅁ
✅ 번역 품질을 측정하기 위해 BLEU 지표 활용

✅ 예제 없이 GPT-4로 첫 번째 시도를 수행한 결과, BLEU 점수 62점을 받아 꽤 괜찮은 결과 보임
✅ 몇 가지 few-shot 예제 추가해, 모델에게 원하는 출력 스타일 학습할 수 있는지 확인해보기
✅ 예제는 다음과 같음:

✅ 전반적인 번역 품질이 개선되어, BLEU 점수가 70점(8%⬆️)
✅ 꽤 좋은 결과이며, 모델에 예제를 제공하는 것이 학습에 도움이 되고 있음을 보여줌
✅ 위의 예제를 통해, 최적화해야되는 것은 모델의 동작임을 보여줌
✅ 문제를 해결하는 지식을 가지고 있다면, 더 많은 예시들을 제공하는 것이 최적화 방법
✅ 이 글의 마무리에서 고급 최적화 방법이 이 use case에서 어떻게 동작하는지 테스트해 볼 예정
✅ 프롬프트 엔지니어링은 최적화를 하기에 좋은 방법이며, 올바른 튜닝 방법 사용하면 성능 크게 향상시킬 수 있다는 점 확인
✅ 하지만, 프롬프트 엔지니어링의 가장 큰 문제는 확장성이 떨어지는 경우가 많다는 것
✅ 모델이 동적인 컨텍스트를 처리하거나(단순한 컨텍스트 채우기보다 ) or few-shot 예제에서 얻을 수 있는 것처럼 일관되게 동작하기 원함
🏊♀️ 더 깊이 알아보기(Deep Dive)
긴 문장 사용해 프롬프트 엔지니어링 확장하기
Long-context 모델 사용하면 프롬프트 엔지니어링 더욱 확장할 수 있음
하지만, 복잡한 지침이 포함된 매우 큰 프롬프트의 경우, 모델이 attention을 유지하기 어려울 수 있음
따라서, 항상 long-context 모델과 다양한 컨텍스트의 크기의 평가를 같이 진행해 "lost in the middle" 문제를 예방해야 함
"Lost in the middle"은 LLM이 한번에 주어진 모든 토큰에 동일한 attention을 줄 수 없다는 것 의미
이로 인해 정보가 무작위로 누락될 수 있음
그렇다고 해서 긴 문장을 사용해서는 안 된다는 의미는 아니지면, 철저한 평가를 거친 후 사용해야 함
오픈소스 기여자 중 1명인 Greg Kamradt는 NITA(Needle in A Haystack)라는 유용한 평가 방법 만들었음
긴 문장의 문서에 다양한 깊이의 정보 숨기고 검색 품질 평가하는 방법
긴 문장의 문제점을 잘 보여줌
문서에서 모든 것을 건너뛰어 훨씬 더 간단한 검색을 보이지만, 정확도에서는 성능이 떨어질 수 있음
✅ 실제로 프롬프트 엔지니어링으로는 어디까지 할 수 있을까?
✅ 답은 상황에 따라 따르며, 평가 결과를 기반으로 결정을 내려야 함
평가
✅ 그렇기 때문에, 이 단계에서 가장 좋은 결과물은 평과 질문-ground truth 답변이 포함된 좋은 프롬프트
✅ 20개 이상의 질문과 답변이 있고, 왜 잘못된 답변이 나왔는지 분석해 가설을 세웠다면, 고급 최적화 방법 시도할 수 있음
✅ 보다 정교한 최적화 방법으로 넘어가기 전에, 이 평가를 자동화해 반복 작업의 속도 높이는 방법도 고려해 볼 가치 있음
✅ 효과적인 것으로 확인된 몇 가지 일반적인 방법은 다음과 같음
- ROUGE 또는 BERT Score와 같은 평가 방법 사용해 직관적 판단 내리기. 사람이 평가하는 것과 그다지 차이는 없지만, 횟수가 반복되며 모델 출력이 얼마나 변화하는지 빠르고 효과적으로 측정할 수 있음
- G-EVAL 논문에 설명된 대로 GPT-4를 평가자로 사용해 LLM에 스코어카드 제공하면, 최대한 객관적으로 결과물 평가
✅ 이 방법들을 더 자세히 알아보고 싶다면 cookbook에서 모든 방법 실제로 살펴볼 수 있음
Tool 이해하기
✅ 프롬프트 엔지니어링 완료하고, 평가 데이터셋을 확보했지만 모델이 여전히 필요한 기능을 수행하지 못하고 있는 상황
✅ 그런 상황이라면 가장 중요한 다음 단계는 어디에서 문제 발생했는지 진단하고, 이를 개선하는데 가장 효과적인 tool 찾는 것
✅ 다음은 이를 위한 기본 프레임워크

✅ 실패한 평가 질문을 In-context 또는 Learned memory 문제로 구성
✅ 비유를 하자면, 시험지를 작성한다고 가정
✅ 정답을 맞힐 수 있는 방법에는 2가지가 있음
- (학습된 메모리) 6개월 동안 수업 들으면서 특정 개넘이 어떻게 동작하는지에 대해 반복적인 예시들을 많이 봄. 프롬프트와 예상되는 답변의 예시를 보여주고 이를 학습한 모델을 보여줌으로써 LLM으로 문제 해결
- (In-context 메모리) 교과서를 가지고 있으면, 질문에 답할 수 있는 올바른 정보 찾을 수 있음. context window에 관련 정보 채워 넣는 방식으로 LLM에서 이를 해결. 프롬프트 엔지니어링 사용하는 정적 방법 or 산업적인 방법의 RAG
✅ 이 2가지 최적화 방법은 상호 보완적이며, 일부 use case에서는 최적의 성능 위해 함께 사용되기도 함
✅ 단기 메모리 문제가 발생해, RAG를 사용한다고 가정하기
Retrieval-augmented generaiton(RAG)
✅ RAG는 답변을 생성하기 전에 LLM의 프롬프트를 증강하기 위해 문서들을 검색하는 과정
✅ 이는 모델이 답변하기 위해 도메인별 내용에 접근할 수 있도록 하는데 사용됨
✅ RAG는 LLM의 정확도와 일관성을 높이는데 매우 유용한 tool
✅ OpenAI의 대규모 고객 배포 중 상당수가 프롬프트 엔지니어링과 RAG만을 사용해 이루어짐

✅ 위의 예시에서는 통계에 대한 knowledge base를 임베딩함
✅ 사용자가 질문하면, 해당 질문을 임베딩하고, knowledge base에서 가장 관련성 높은 콘텐츠 검색
✅ 이 콘텐츠는 모델에 전달되어, 질문에 대한 답변 제공
✅ RAG 어플리케이션은 "검색"이라는 최적화해야 할 새로운 영역
✅ RAG가 동작하려면, 모델에 올바른 컨텍스트 전달해야 하고, 이 컨텍스트 가지고 모델이 정확하게 답변했는지 평가해야 함
✅ RAG를 사용한 평가 방법을 아래 좌표평면상에 간단히 표현할 수 있음

✅ RAG Application이 해결할 수 있는 영역은 크게 아래 2가지

✅ 주목해야 할 점은, 무엇이 잘못되었는지 평가해 문제를 파악하고 이를 해결할 수 있는 최적화 단계 밟는 것
✅ RAG는 유용하지만 In-context 학습 문제만 해결해줌
✅ 실제 많은 use case에서의 문제는 LLM이 학습을 일관되고 안정적으로 수행할 수 있도록 하는 것
✅ 이 문제를 해결할 수 있는 것이 파인튜닝
파인 튜닝
✅ 학습된 메모리 문제 해결하기 위해 많은 개발자는 특정 작업에 맞게 최적화하기 위해 더 작은 도메인별 데이터에서 LLM 학습 진행
✅ 이 과정을 파인튜닝이라고 함
✅ 파인 튜닝은 일반적으로 아래 2가지 이유 중 하나로 수행됨
- 특정 작업에 대한 모델 정확도 개선하기 위해: 작업별 데이터로 모델을 학습시켜, 해당 작업이 올바르게 수행되는 많은 예시를 보옂움으로써 학습된 메모리 문제 해결
- 모델 효율성 개선: 더 작은 토큰 사용하거나 더 작은 모델 사용해 동일한 정확도 달성
✅ 파인 튜닝 과정은 훈련 예제의 데이터셋을 준비하는 것으로 시작되며, 파인 튜닝 예제는 모델이 실제 세계에서 마주하게 될 것을 정확히 나타내야 하므로 이 단계가 가장 중요
많은 고객이 파일럿 기간 동안 프롬프트 입력 및 출력을 광범위하게 기록하는 프롬프트 베이킹(prompt baking) 과정 사용
이런 로그는 현실적인 예제 통해 효과적인 훈련 데이터셋으로 정리할 수 있음

실제 서비스에 "충분한" 정확도란?
✅
✅
✅
비즈니스
✅ 비즈니스 측면에서 규칙 기반 또는 머신 러닝, 인간에 비해 상대적으로 확실성 떨어지는 LLM 신뢰하기 어려울 수 있음
✅ 예측할 수 없고, 잘못된 답변이 나올 수도 있는 LLM 시스템
✅ Use Case에서 성공적이었던 접근 방식은 다음과 같음
✅ 먼저, 주요 성공 사례와 실패 사례 파악해 예샹 비용 할당
✅ 이렇게 하면 파일럿 성과 기반으로 솔루션이 절약하라 수 있는 금액을 명확하게 파악할 수 있음
- 예를 들어, 사람이 해결했던 일을 AI가 해결하면 20달러 절약할 수 있음
- 인간에게 40달러 비용 발생
- 최악의 시나리오로, 고객이 AI에 너무 실망해 이탈하여 1,000달러 비용 발생. 이런 경우는 5% 확률로 발생한다고 가정
기술
앞으로의 방향성
✅
✅
'LLM' 카테고리의 다른 글
| 딥러닝 GPU 추천(작성중) (2) | 2024.08.28 |
|---|---|
| LLM 서비스하는데 필요한 GPU 메모리 계산하기 (2) | 2024.08.26 |
| [인공지능] 구글 딥마인드에서 정의한 AGI 5단계(규칙 기반 에이전트 ~ 자율 에이전트) (1) | 2024.07.11 |
| [SK TECH SUMMIT 2023] LLM 적용 방법인 RAG VS PEFT, Domain 적용 승자는? (1) | 2024.05.02 |